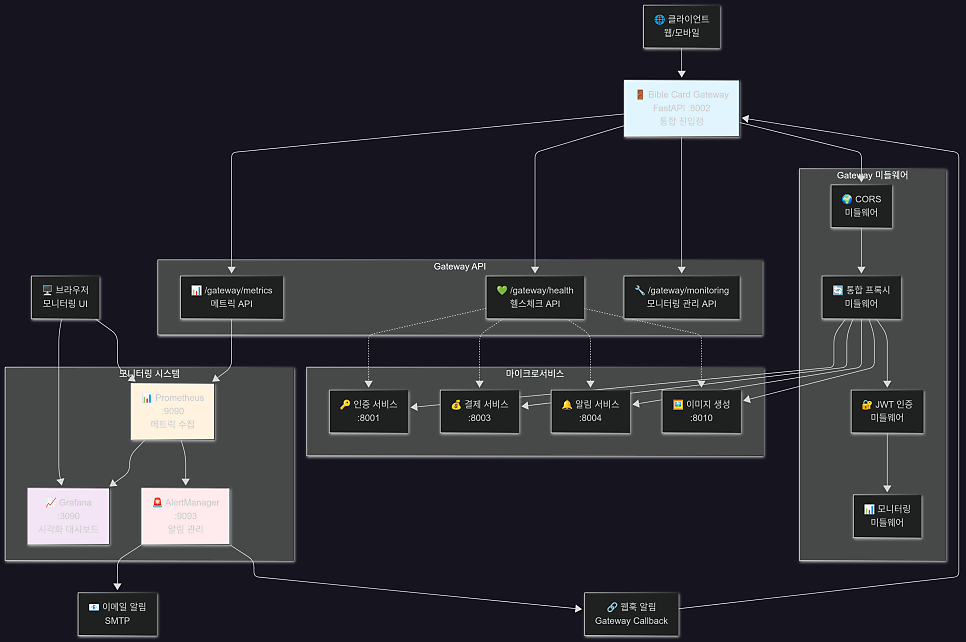
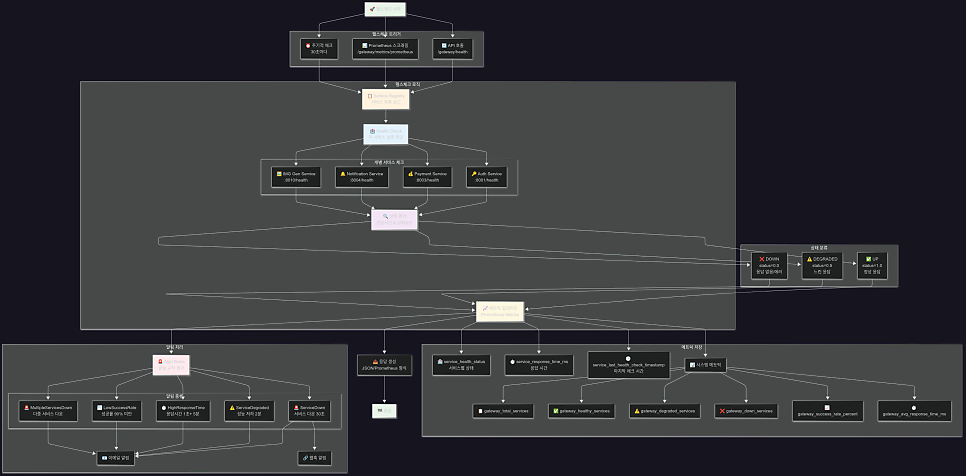
게이트웨이 모니터링 시스템의 서버 구조, 헬스체크 플로우 with Prometheus, Grafana, AlertManager
- Gateway (FastAPI :8002) - 단일 진입점
- 미들웨어 레이어 - CORS, 프록시, 인증, 모니터링
- 마이크로 서비스들 - Auth, Payment, Notification, ImgGen
- 모니터링 스택 - Prometheus, Grafana, AlertManager
- 알림 채널 - 이메일, 웹훅
- 트리거: API 호출, Prometheus 스크래핑, 주기적 체크
- 상태 평가: UP(1.0), DEGRADED(0.5), DOWN(0.0)
- 메트릭 생성: 11개 핵심 메트릭 (service_health_status 등)
- 알림 처리: 5가지 알림 규칙 (ServiceDown, Degraded 등)

[영상]
아래는 각 항목의 모니터링 시스템에 쓰인 변수들의 의미와 사용 목적에 대한 설명입니다:
🟢 Prometheus 스크래핑 설정 Prometheus는 주기적으로 타겟 서버의 메트릭을 “스크래핑(scraping)”합니다. 이 설정들은 그 주기를 지정합니다.
| 항목 | 의미 |
|---|---|
| PROMETHEUS_GLOBAL_SCRAPE_INTERVAL=15s | 기본 스크래핑 주기 (모든 타겟에 적용되는 기본값) – 15초마다 메트릭 수집 |
| PROMETHEUS_GLOBAL_EVALUATION_INTERVAL=15s | 룰(경고 룰 등)을 평가하는 주기 – 15초마다 Alert Rule 등 평가 |
| PROMETHEUS_GATEWAY_SCRAPE_INTERVAL=10s | API Gateway(예: FastAPI) 서버의 메트릭 수집 주기 – 10초마다 |
| PROMETHEUS_SELF_SCRAPE_INTERVAL=30s | Prometheus 자체 메트릭 수집 주기 – 30초마다 |
| PROMETHEUS_GRAFANA_SCRAPE_INTERVAL=30s | Grafana 메트릭 수집 주기 – 30초마다 |
| PROMETHEUS_ALERTMANAGER_SCRAPE_INTERVAL=30s | AlertManager 메트릭 수집 주기 – 30초마다 |
💡 보통 중요한 애플리케이션일수록 짧은 주기, 중요도가 낮으면 긴 주기로 설정
🔵 헬스체크 설정 (Docker 등에서 사용) 컨테이너가 “정상인지” 주기적으로 검사하는 설정입니다.
| 항목 | 의미 |
|---|---|
| HEALTHCHECK_INTERVAL=30s | 헬스체크를 수행하는 주기 – 30초마다 상태 점검 |
| HEALTHCHECK_TIMEOUT=10s | 헬스체크 명령이 실패 판정되기까지 기다리는 시간 – 10초 이상 응답 없으면 실패 |
| HEALTHCHECK_RETRIES=3 | 연속 실패 허용 횟수 – 3회 실패하면 컨테이너를 “비정상”으로 간주 |
🔴 AlertManager 알림 관련 설정 Prometheus에서 조건을 만족하면 AlertManager에 알림이 전달되고, 그 이후 알림 그룹을 어떻게 전송할지 정의합니다.
| 항목 | 의미 |
|---|---|
| ALERT_GROUP_WAIT=10s | 처음 알림이 감지되었을 때, 동일 그룹의 다른 알림을 기다리는 시간 – 10초 기다렸다가 그룹으로 묶어서 보냄 |
| ALERT_GROUP_INTERVAL=10s | 동일한 그룹에서 새 알림이 생겼을 때, 기존 그룹 알림 이후 얼마나 있다가 보낼지 – 10초 간격 |
| ALERT_REPEAT_INTERVAL=1h | 동일 알림을 반복 전송할 간격 – 같은 문제가 해결되지 않았을 때 1시간 후 재전송 |
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.