[1부] 스토리북 자동화 처리 시스템 구축기: 파이프라인 설계와 안정성 확보

들어가며… ** AI와 자동화 기술이 콘텐츠 생산 방식을 혁신하고 있는 시대입니다.
저는 수천 개의 스토리북을 자동으로 고품질 동영상으로 변환하는 시스템을 구축했습니다.
https://youtu.be/jT7rtcun6zQ?si=oLrdVqnugTrNf9Im
[영상]
https://blog.naver.com/devramyun/223827566870
[20250409] [Python] sleep(0.5) 한 줄로 잡은 실무 버그 2가지 – 파일 손상과 동시성 문제 해결기 개발을 하다 보면, sleep()이라는 함수는 대부분 “성능을 떨어뜨리는 느린 코드”라고 생각하기 … 개발을 하다 보면, sleep()이라는 함수는 대부분 “성능을 떨어뜨리는 느린 코드”라고 생각하기 …
https://blog.naver.com/devramyun/223786116674
[20250306] 프로그램으로 만든 동화책 전체 결과(검색비허용) fps를 높이면 그만큼 렌더링 시간도 많이 걸립니다. 좋은 결과도 공유드리고 여기 블로그에 남기고 싶어서 … fps를 높이면 그만큼 렌더링 시간도 많이 걸립니다. 좋은 결과도 공유드리고 여기 블로그에 남기고 싶어서 …
이 시리즈에서는 그 과정과 방법을 공유하려고 합니다.
이 1부에서는 전체 파이프라인의 설계와 안정성 확보 방법에 초점을 맞추겠습니다.
2부에서는 동영상 생성 엔진의 세부 구현과 전체 시스템 통합에 대해 다룰 예정입니다.
- 콘텐츠 다운로드: API에서 스토리북 데이터를 가져와 로컬에 구조화된 형태로 저장
- 동영상 생성: 다운로드된 콘텐츠를 처리하여 고품질 MP4 비디오 생성
- 결과물 배포: 완성된 동영상과 오디오 파일을 FTP 서버로 업로드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def process_book_queue():
while True:
# 1. READY 상태의 책 가져오기
ready_books = get_ready_books()
if not ready_books:
logger.info("📚 처리할 책이 없습니다. 60초 대기...")
time.sleep(60)
continue
# 2. 첫 번째 책을 PROCESSING으로 변경
book_id = ready_books[0]["bookId"]
current_processing_book_id = book_id # 현재 처리 중인 책 ID 저장
update_status(book_id, f"PROCESSING({COMP_INDEX})")
try:
# 3. 처리 단계 실행
if not download_book(book_id):
update_status(book_id, f"ERROR({COMP_INDEX})")
continue
if not generate_video(book_id):
update_status(book_id, f"ERROR({COMP_INDEX})")
continue
if not upload_to_ftp(book_id, sb):
update_status(book_id, f"ERROR({COMP_INDEX})")
continue
update_status(book_id, f"COMPLETED({COMP_INDEX})")
except Exception as e:
logger.error(f"⚠️ 처리 중 오류 발생: {str(e)}")
update_status(book_id, f"ERROR({COMP_INDEX})")
- READY: 처리 대기 중
- PROCESSING(n): 서버 n에서 처리 중
- ERROR(n): 서버 n에서 오류 발생
- COMPLETED(n): 서버 n에서 처리 완료
1
2
3
4
def update_status(bookid, status):
payload = {"serverid": SERVER_ID, "bookid": str(bookid), "status": status, "gbn": "mp4"}
requests.post(STATUS_UPDATE_URL, json=payload)
logger.info(f"📤 상태 업데이트: {bookid} -> {status}")
안정성과 오류 복원력 확보 ** 프로덕션 환경에서 24/7 운영되는 시스템의 가장 중요한 특성은 안정성입니다.
다음과 같은 메커니즘을 통해 견고한 오류 복원력을 구현했습니다.
데코레이터를 활용한 자동 재시도 로직 ** 파이썬의 데코레이터 패턴을 활용하여 네트워크 호출, 파일 다운로드 등의 불안정한 작업에 자동 재시도 로직을 적용했습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def retry_on_failure(max_retries=2, delay=5):
"""실패 시 재시도하는 데코레이터"""
def decorator(func):
def wrapper(*args, **kwargs):
global logger
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except Exception as e:
if attempt == max_retries - 1: # 마지막 시도
if logger:
logger.error(f"최대 재시도 횟수 초과: {str(e)}")
raise
if logger:
logger.warning(f"시도 {attempt + 1}/{max_retries} 실패: {str(e)}")
time.sleep(delay)
return None
return wrapper
return decorator
@retry_on_failure(max_retries=2, delay=5)
@log_execution
def download_book(bookid) -> bool:
# 다운로드 로직...
이 데코레이터는 함수 실행 중 예외가 발생하면 자동으로 설정된 횟수만큼 재시도하며, 시도 사이에 지정된 시간을 대기합니다. 이를 통해 일시적인 네트워크 오류나 자원 경합 문제 등을 우아하게 처리할 수 있습니다.
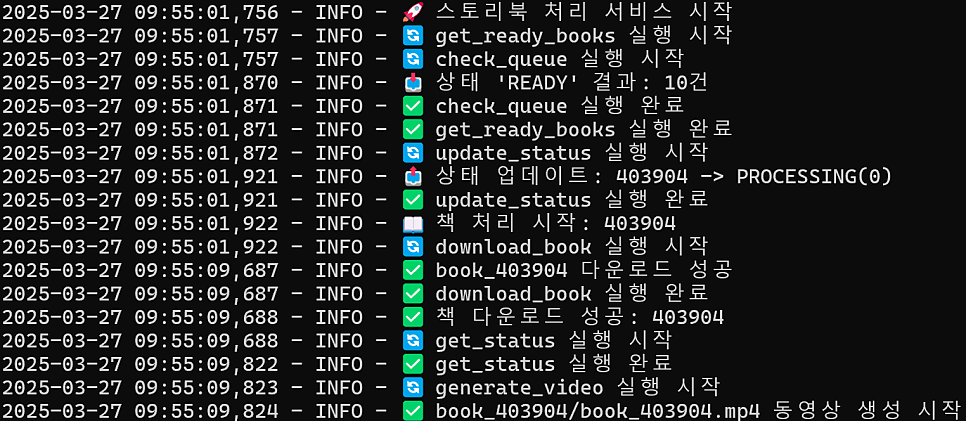
체계적인 로깅 시스템 ** 모든 작업은 상세하게 기록되어 문제 해결과 모니터링을 용이하게 합니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def setup_logger():
"""로거 설정"""
# 로거 설정
logger = logging.getLogger("StoryQueueProcessor")
# 로그 디렉토리 생성
log_dir = os.path.join(get_base_path(), "logs")
os.makedirs(log_dir, exist_ok=True)
# 로그 파일명 설정 (날짜별)
log_file = os.path.join(log_dir, f"storybook_{datetime.now().strftime('%Y%m%d')}.log")
# 파일 핸들러 설정 (최대 10MB, 백업 5개)
file_handler = RotatingFileHandler(log_file, maxBytes=10 * 1024 * 1024, backupCount=5, encoding="utf-8")
# 포맷 설정
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
file_handler.setFormatter(formatter)
# 핸들러 추가
logger.addHandler(file_handler)
return logger
로그는 다음과 같이 구조화되어 출력됩니다:
1
2
3
2023-05-15 14:23:45 - INFO - 🔄 download_book 실행 시작
2023-05-15 14:23:47 - INFO - ✅ book_380238 다운로드 성공
2023-05-15 14:23:47 - INFO - ✅ download_book 실행 완료
이 로그는 자동으로 날짜별로 파일이 분리되고, 각 파일은 10MB 크기에 도달하면 로테이션되며, 최대 5개의 백업 파일이 유지됩니다. 이는 장기간 실행되는 서비스에서 디스크 공간 문제를 방지합니다.
우아한 종료 처리 ** 프로그램이 중단되더라도 데이터 일관성을 유지하는 것이 중요합니다.
이 시스템은 사용자가 Ctrl+C로 종료하거나 예기치 않은 종료 상황에서도 현재 처리 중인 책의 상태를 정확히 업데이트합니다:
1
2
3
4
5
6
7
8
9
10
11
12
try:
# 메인 로직
except KeyboardInterrupt:
logger.info("👋 사용자에 의해 종료됨")
# 현재 처리 중인 책이 있으면 ERROR 상태로 업데이트
if current_processing_book_id:
logger.info(f"⚠️ 처리 중이던 책 {current_processing_book_id}를 ERROR 상태로 변경")
update_status(current_processing_book_id, f"ERROR({COMP_INDEX})")
except Exception as e:
logger.error(f"⚠️ 오류: {str(e)}")
finally:
logger.info("👋 서비스 종료")
이렇게 하면 처리가 중단된 책은 ERROR 상태로 표시되어 나중에 다시 처리될 수 있습니다.
유연한 설정 관리 ** 운영 환경에서는 설정 변경이 자주 필요하며, 이를 위해 코드 수정 없이 설정을 변경할 수 있는 유연한 시스템을 구현했습니다.
환경 변수와 .env 파일 ** 민감한 정보와 환경별 설정을 코드와 분리하여 .env 파일과 환경 변수로 관리합니다:
1
2
3
4
5
6
7
8
from dotenv import load_dotenv
load_dotenv() # .env 파일 로드
# FTP 설정
FTP_HOST = os.getenv("FTP_HOST", "real.ai")
FTP_PORT = int(os.getenv("FTP_PORT", "12345"))
FTP_USER = os.getenv("FTP_USER", "user")
FTP_PASS = os.getenv("FTP_PASS", "pwd")
이를 통해 개발, 테스트, 프로덕션 등 다양한 환경에서 코드 변경 없이 설정을 조정할 수 있습니다.
명령줄 인터페이스 ** 시스템은 다양한 명령을 지원하는 명령줄 인터페이스를 제공합니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def main():
# 명령줄 인수 파서 설정
parser = argparse.ArgumentParser(description="스토리북 처리 서비스")
parser.add_argument("command", nargs="?", default="process",
choices=["process", "reset-error", "reset-processing"],
help="실행할 명령어 (기본값: process)")
parser.add_argument("--comp-index", type=str, default=os.getenv("COMP_INDEX", "0"),
help="서버 ID (기본값: 환경변수 COMP_INDEX 또는 0)")
args = parser.parse_args()
# 명령에 따른 처리
if args.command == "process":
process_book_queue()
elif args.command == "reset-error":
reset_error_books()
elif args.command == "reset-processing":
reset_processing_books()
이를 통해 다음과 같은 다양한 작업을 수행할 수 있습니다:
1
2
3
4
5
6
7
8
9
10
11
# 기본 처리 모드
./스토리큐프로세서.exe
# 오류 상태 책 초기화
./스토리큐프로세서.exe reset-error
# 처리중 상태 책 초기화
./스토리큐프로세서.exe reset-processing
# 서버 ID 지정 실행
./스토리큐프로세서.exe --comp-index 1
- 자동화 효율: 이전에 수동으로 10분 이상 걸리던 과정이 완전 자동화되어 24시간 무인 운영 가능
- 안정적 운영: 네트워크 오류, 서버 문제 등 다양한 예외 상황에서도 복원력 유지
- 확장성: COMP_INDEX를 통한 분산 처리로 처리량 수평적 확장 가능
- 유지보수성: 모듈화된 설계와 상세한 로깅으로 유지보수 및 문제 해결 용이

다음 내용 예고 ** 이 포스트에서는 스토리북 자동화 시스템의 전체 구조와 안정성 확보 방법에 대해 알아보았습니다.
[2부]에서는 파이프라인의 핵심인 동영상 생성 엔진의 세부 구현 방법과 세 가지 핵심 컴포넌트가 어떻게 통합되어 완전한 엔드투엔드 솔루션을 구성하는지 살펴보겠습니다.
또한 실제 운영 환경에서의 성능 데이터와 최적화 기법에 대해서도 다룰 예정입니다.

[2부] https://blog.naver.com/devramyun/223811494542
[2부] 스토리북 자동화 처리 시스템 구축기: 동영상 생성 엔진과 엔드투엔드 통합 들어가며 [1부]에서는 스토리북 자동화 시스템의 전체 구조와 안정성 확보 방법에 대해 알아보았습니다. 이… 들어가며 [1부]에서는 스토리북 자동화 시스템의 전체 구조와 안정성 확보 방법에 대해 알아보았습니다. 이…
#python_그림책낭독_동영상자동생성_cli_클라이언트_빌드