타이타닉 데이터로 F1 Score을 최대화하는 데이터분석 앙상블 모델 구현, 결과 내기
아래 포스팅을 참조해서 타이타닉 데이터를 가지고 모델 앙상블로 f1 score 0.8 이상을 달성해보겠습니다. [https://datainclude.me/posts/%ED%83%80%EC%9D%B4%ED%83%80%EB%8B%89%ED%83%914%EC%95%99%EC%83%81%EB%B8%94%EB%AA%A8%EB%8D%B8%EB%A7%81/](https://datainclude.me/posts/%ED%83%80%EC%9D%B4%ED%83%80%EB%8B%89%ED%83%914%EC%95%99%EC%83%81%EB%B8%94%EB%AA%A8%EB%8D%B8%EB%A7%81/)
타이타닉 탑4% 앙상블 모델링 1 Introduction 2 Load and check data 2.1 load data 2.2 Outlier detection 2.3 joining train and test set 2.4 check for null and missing values 3 Feature analysis 3.1 Numerical values 3.2 Categorical values 4 Filling missing Values 4.1 Age 5 Feature engineering 5.1 Name/Title 5.2 Family Size 5.3 Cabin… 1 Introduction 2 Load and check data 2.1 load data 2.2 Outlier detection 2.3 joining train and test set 2.4 check for null and missing values 3 Feature analysis 3.1 Numerical values 3.2 Categorical values 4 Filling missing Values 4.1 Age 5 Feature engineering 5.1 Name/Title 5.2 Family Size 5.3 Cabin…
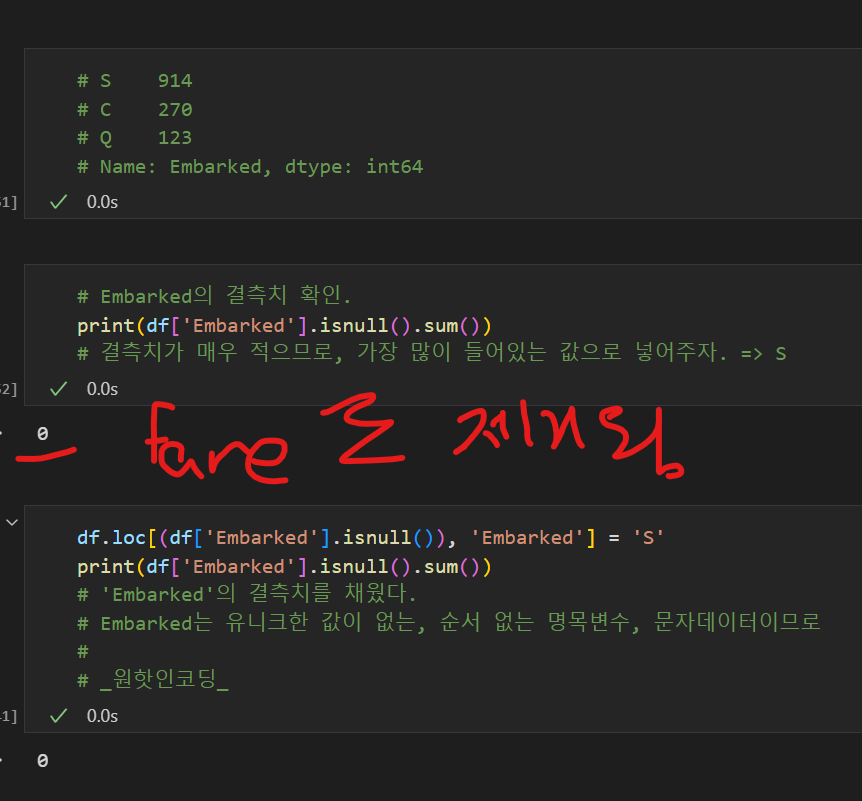
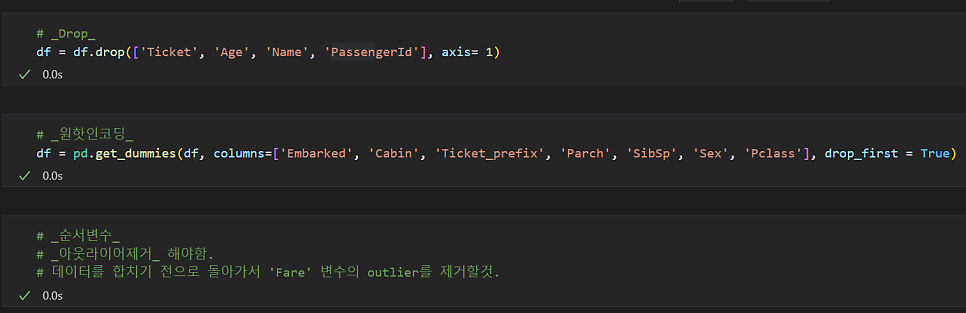
train데이터의 아웃라이어는 데이터를 합치기 전에 제거해줘야 함.
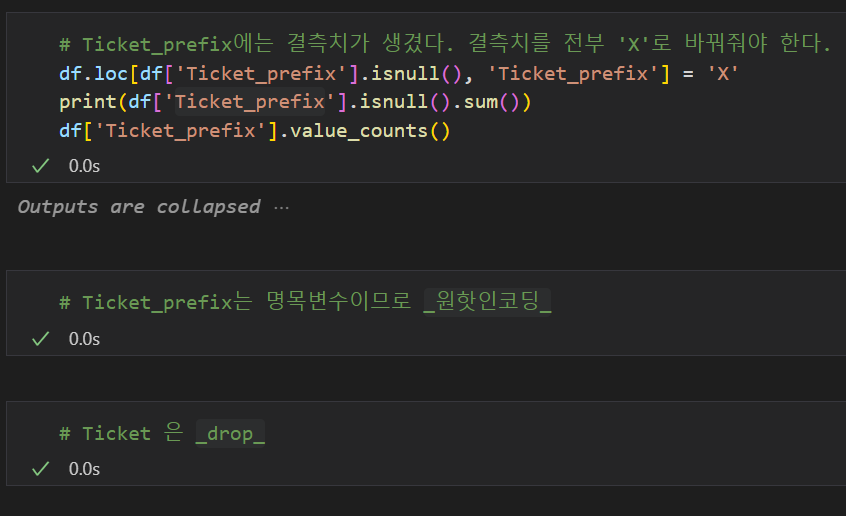
df['Ticket'].str.extract('([^ \n\t\r\f\v]+) ')
1
df['Ticket'].str.extract('([^ \n\t\r\f\v]+) ')
EDA를 한 후의 전체 데이터를 다시 훈련데이터, 테스트데이터로 나눔. 테스트 데이터에서 라벨을 드롭하고 훈련데이터에서도 라벨을 드롭한 X_train과 나머지인 Y_train을 나눔.
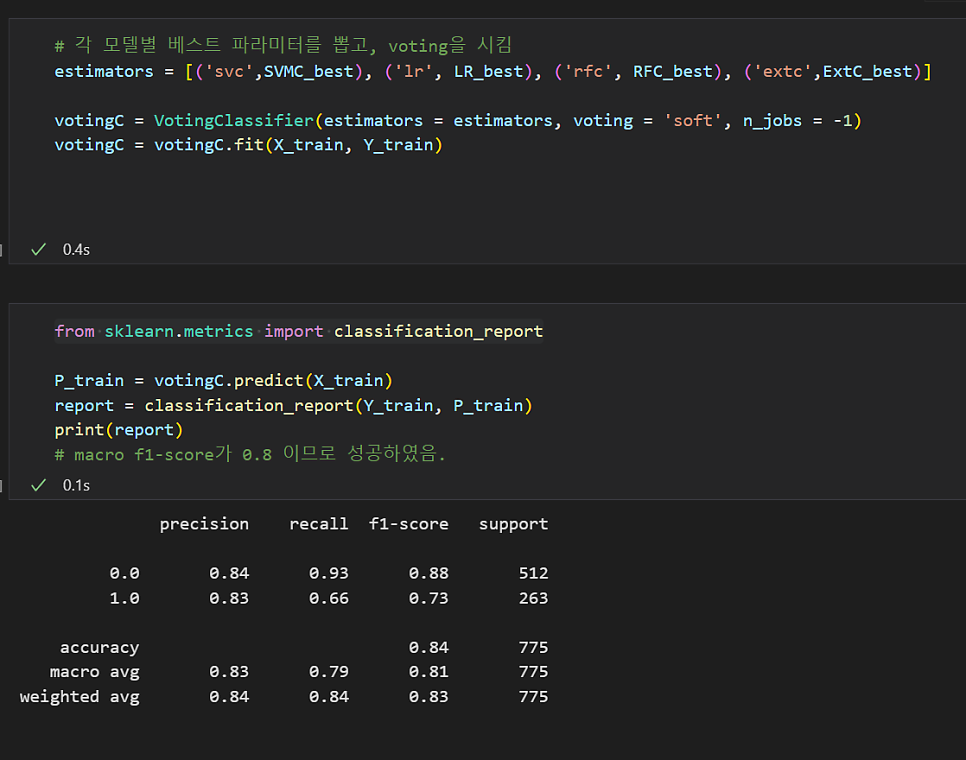
(f1-score > 0.8) 성공!
추가로 테스트 데이터 예측도 해볼 수 있음. 테스트데이터에는 정답 라벨이 없으므로 리포트는 못냄.
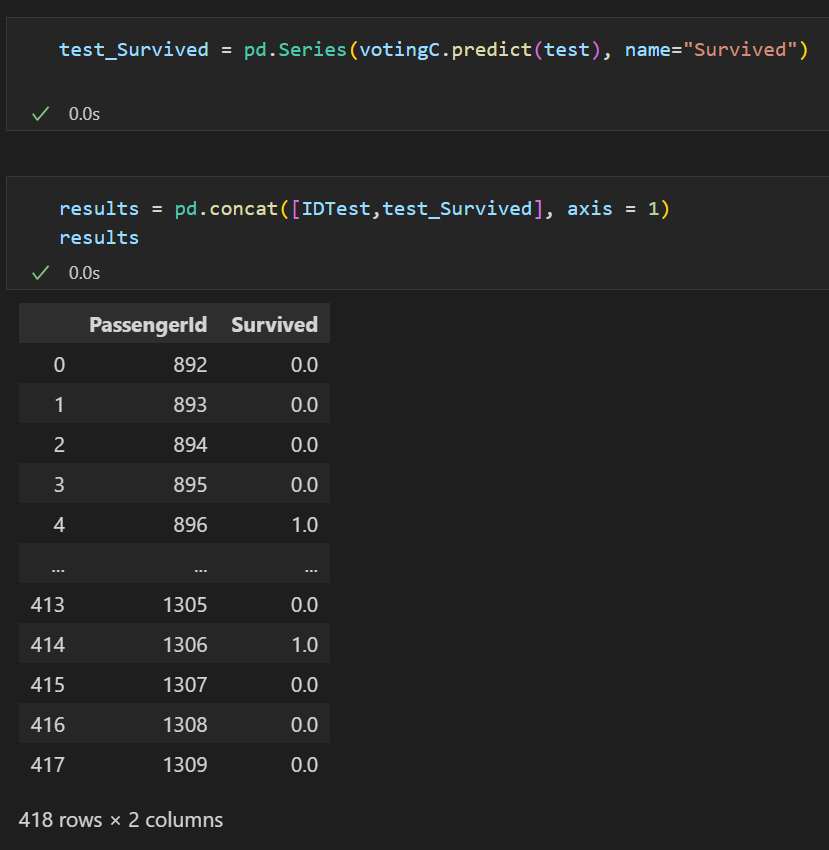
이걸로 끝인데… 이걸 2시간 안에 풀어야..? 너무 외울게 많은데요 ㅎㅎ….
시험 때도 chatgpt와 함께했으면 좋겠..네요 ㅠ 허락이 안되겠죠? ㅎㅎ
1
2
3
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
1
2
3
4
5
6
7
# _데이터 불러오고 개수 세서 합치기_
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
ntrain = train.shape[0]
ntest = test.shape[0]
df = pd.concat((train, test))
1
2
3
# _유니크 값 보고 EDA시작하기
for column in df.columns:
print(df[column].value_counts())
명목변수와 순서변수로 나눠 생각.
1
2
# 조건에 맞는 시리즈만 떼어내서 수정하기
df.loc[df['칼럼'].isnull(), '칼럼'] = ~
1
2
# _drop_
df = df.drop(['칼럼1', '칼럼2'], axis=1)
1
2
# _원핫인코딩_
df = df.get_dummies(df, columns=['칼럼1', '칼럼2'], drop_first=True)
1
2
3
4
5
6
7
8
9
10
11
# 합치기 전으로 돌아가서 학습데이터 _아웃라이어_제거하기
Q1 = (25%값)
Q3 = (75%값)
IQR = Q3-Q1
MIN = Q1-1.5*IQR
MAX = Q3+1.5*IQR
print(MIN)
print(MAX)
# train = train[train['Fare'] > MIN]
# train = train[train['Fare'] MIN)&(train['Fare']<MAX)]
plt.boxplot(train['Fare'])
1
2
3
4
X_test = test.drop(['라벨 컬럼'], axis=1)
X_train = train.drop(['라벨 컬럼'], axis=1)
Y_train = train['라벨 컬럼']
1
2
3
4
5
6
7
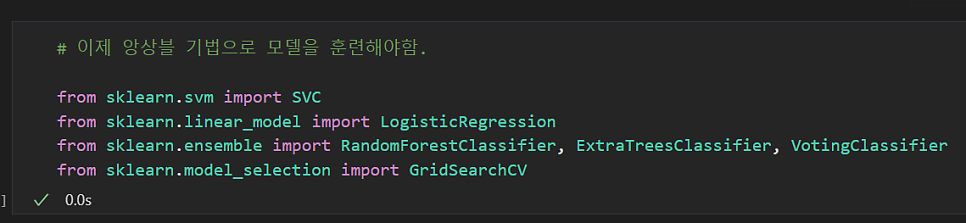
# 앙상블 패키지 가져오기
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, VotingClassifier
from sklearn.model_search import GridSearchCV
… chatgpt가 param_grid를 간단히 바꿔준 걸로 훈련시켰더니 성능이 올라갔다…
1
2
3
4
5
6
7
8
9
10
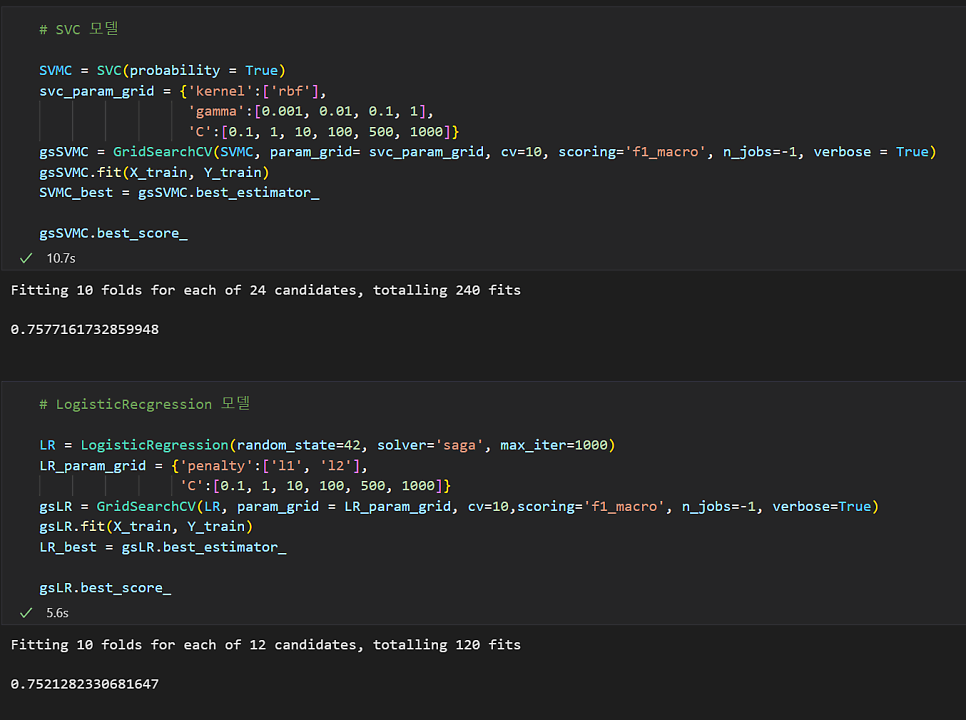
# SVC 모델
SVMC = SVC(probability = True)
svc_param_grid = {'gamma':[0.001, 0.01, 0.1, 1],
'C':[0.1, 1, 10, 100, 500, 1000]}
gsSVMC = GridSearchCV(SVMC, param_grid= svc_param_grid, cv=10, scoring='f1_macro', n_jobs=-1, verbose = True)
gsSVMC.fit(X_train, Y_train)
SVMC_best = gsSVMC.best_estimator_
gsSVMC.best_score_
1
2
3
4
5
6
7
8
9
10
# LogisticRecgression 모델
LR = LogisticRegression(random_state=42, solver='saga', max_iter=1000)
LR_param_grid = {'penalty':['l1', 'l2'],
'C':[0.1, 1, 10, 100, 500, 1000]}
gsLR = GridSearchCV(LR, param_grid = LR_param_grid, cv=10,scoring='f1_macro', n_jobs=-1, verbose=True)
gsLR.fit(X_train, Y_train)
LR_best = gsLR.best_estimator_
gsLR.best_score_
1
2
3
4
5
6
7
8
9
10
11
12
13
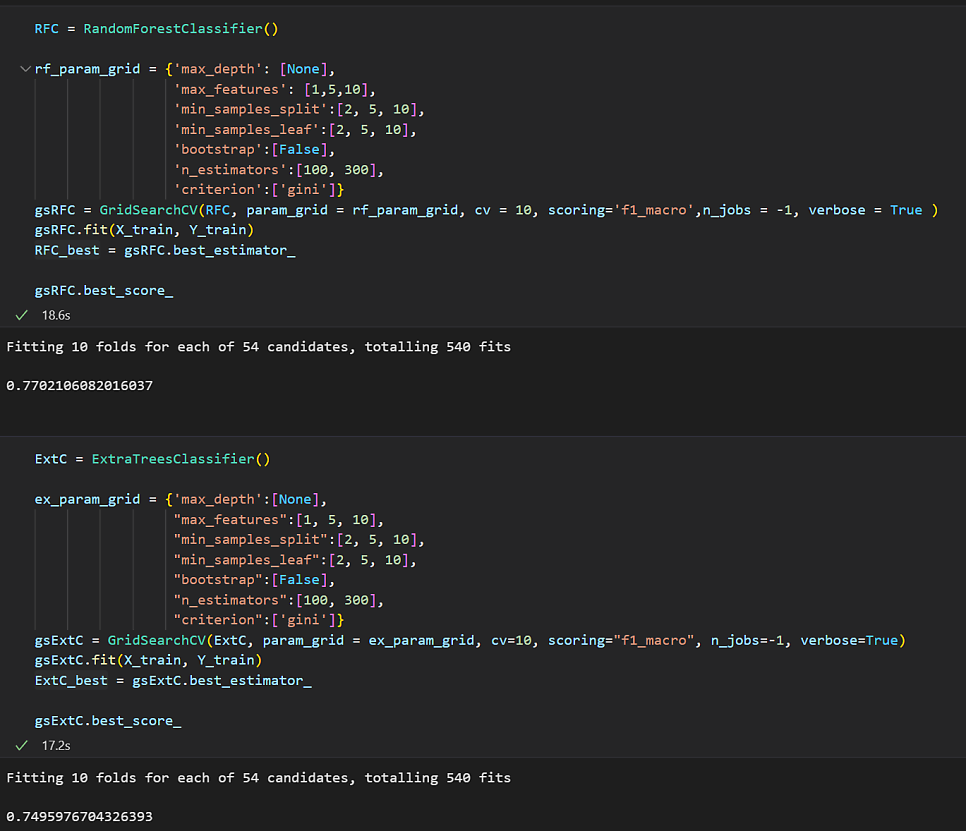
RFC = RandomForestClassifier()
rf_param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
}
gsRFC = GridSearchCV(RFC, param_grid = rf_param_grid, cv = 10, scoring='f1_macro',n_jobs = -1, verbose = True )
gsRFC.fit(X_train, Y_train)
RFC_best = gsRFC.best_estimator_
gsRFC.best_score_
1
2
3
4
5
6
7
8
9
10
11
12
13
ExtC = ExtraTreesClassifier()
ex_param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
}
gsExtC = GridSearchCV(ExtC, param_grid = ex_param_grid, cv=10, scoring="f1_macro", n_jobs=-1, verbose=True)
gsExtC.fit(X_train, Y_train)
ExtC_best = gsExtC.best_estimator_
gsExtC.best_score_
1
2
3
4
5
6
7
8
# 각 모델별 베스트 파라미터를 뽑고, voting을 시킴
estimators = [('svc',SVMC_best), ('lr', LR_best), ('rfc', RFC_best), ('extc',ExtC_best)]
votingC = VotingClassifier(estimators = estimators, voting = 'soft', n_jobs = -1)
votingC = votingC.fit(X_train, Y_train)
1
2
3
4
5
6
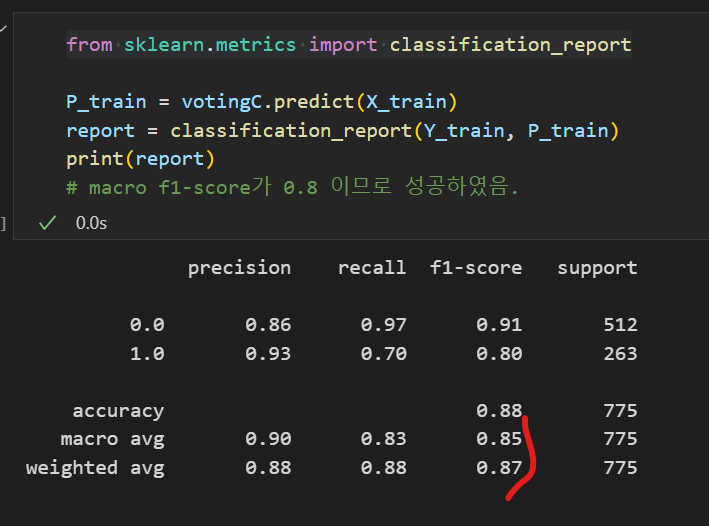
from sklearn.metrics import classification_report
P_train = votingC.predict(X_train)
report = classification_report(Y_train, P_train)
print(report)
# macro f1-score가 0.85 이므로 성공하였음.
모듈 구성요소 생각 안나면 dir(모듈)
1
2
3
4
5
6
7
8
# 결과 제출
P_test = pd.Series(votingC.predict(X_test), name="label")
results = pd.concat([IDtest,P_test],axis=1)
results.to_csv("results.csv",index=False)