페르소나 LoRA를 훈련해서 AdelieAI라는 이름으로 출시했습니다
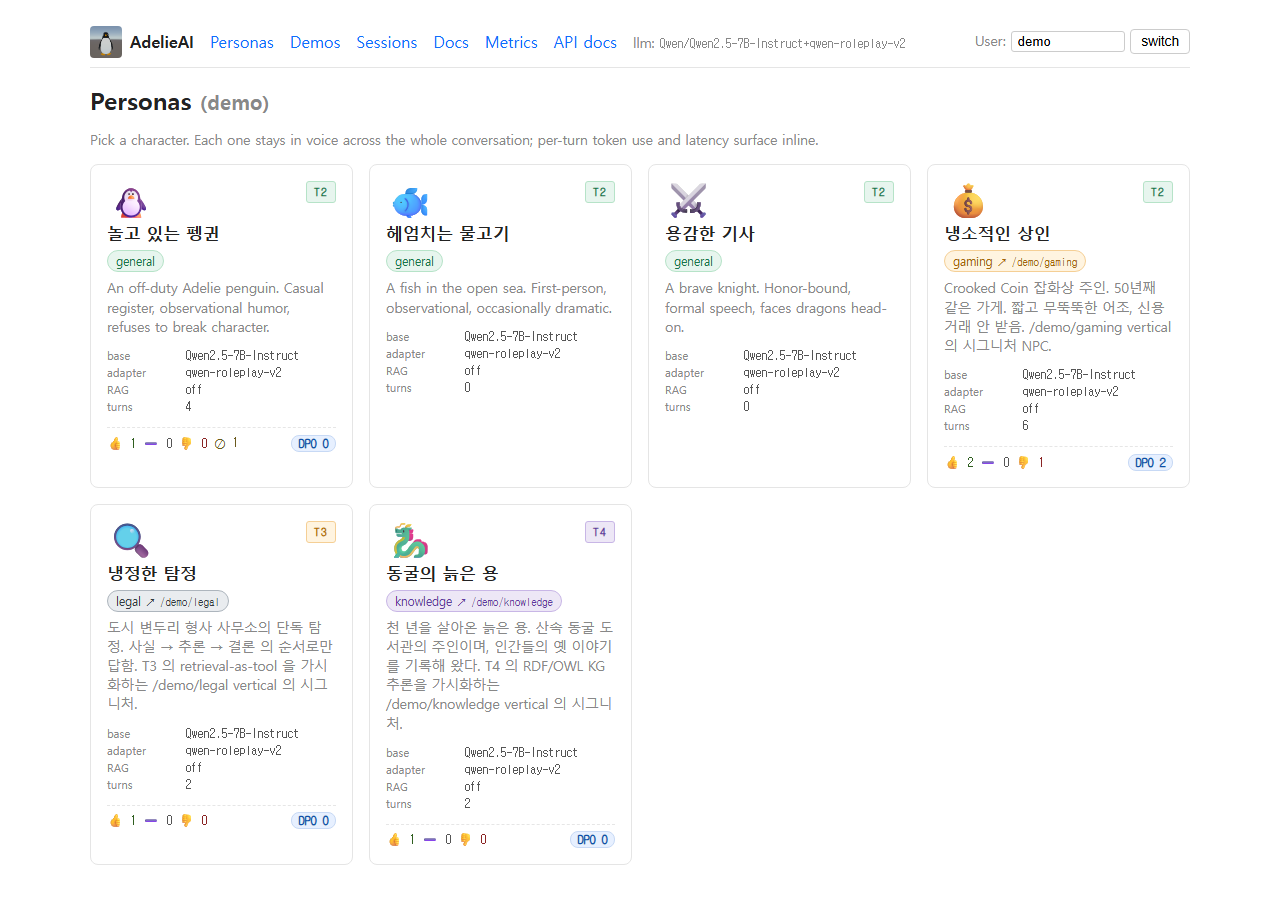
작은 LLM에 페르소나를 직접 훈련시켜서 패키징하는 오픈소스 엔진 AdelieAI를 공개했습니다. 60에서 120쌍 정도의 대화 데이터를 넣으면 캐릭터를 유지하는 LoRA가 나오고, GGUF로 양자화해서 노트북에서도 돌릴 수 있게 만드는 파이프라인입니다. 오늘 두 개의 학습된 체크포인트를 HuggingFace에 같이 올렸습니다.
- 코드: github.com/southglory/AdelieAI
- GPU LoRA: ramyun/adelie-qwen-roleplay-v2-lora
- CPU GGUF: ramyun/adelie-qwen-roleplay-v2-gguf
- 라이선스: 코드 Apache 2.0, 모델 가중치 Tongyi Qianwen v1 (Qwen2.5 상속)
“어시스턴트”라는 추상화의 한계
대부분의 LLM 툴킷은 모델을 “도움이 되는 단일 어시스턴트”로 다룹니다. 이 추상화는 게임 NPC, 브랜드 페르소나, 도메인 전문가 워커, 가상 컴패니언 같은 용도엔 어긋납니다. 이쪽은 정반대를 원하기 때문입니다. 긴 상호작용 동안 캐릭터를 유지하면서, 사용자가 실제로 가진 하드웨어에서 도는 모델이 필요합니다.
까칠한 판타지 상인이 갑자기 “저는 도덕적 판단을 내릴 수 없습니다”라고 답하면 몰입이 깨집니다. 누아르 탐정이 추리 도중에 일반 어시스턴트 모드로 빠지면 장면이 죽습니다. 베이스 모델의 “친절하고 중립적이고 조심스러운” 기본값이 정확히 안 어울리는 부분입니다.
그래서 다음 질문이 출발점이었습니다. 작은 모델을 수백 턴 동안 캐릭터로 유지시키되, 배포 가능한 사이즈로 패키징하고, 호스팅 API에 토큰당 몇 센트를 태우지 않으면서 굴릴 수 있을까. AdelieAI는 그 질문에 대한 답입니다.
파이프라인
페르소나 아이디어에서 배포 가능한 캐릭터까지 가는 흐름입니다.
- 캐릭터 톤에 맞는 대화 60에서 120쌍을 준비합니다
- Qwen 7B 베이스 위에 LoRA 어댑터를 훈련합니다 (3090 한 장에서 25분 정도)
- LLM을 심판으로 쓰는 평가 하네스로 베이스 및 이전 버전과 비교합니다
- 모든 것을
.adelie페르소나 팩(독립 아티팩트 하나)으로 묶습니다 - GGUF q4_k_m으로 양자화합니다 (4.4GB 단일 파일, CPU 노트북에서 추론 가능)
- 게임 NPC, Discord 봇, 고객 지원 워커, CLI 챗 어디에나 투입합니다
.adelie 팩 하나가 일관된 스타일과 (선택적으로) RAG 그라운딩 지식, 그리고 재현 가능한 학습 레시피를 모두 담은 캐릭터 한 명입니다.
콘솔의 세 가지 모드
웹 콘솔에는 세 모드가 있습니다. 인프라는 공유하지만 답하는 질문이 다릅니다.
| 모드 | 답하는 질문 |
|---|---|
Persona (/web/personas) | “이 캐릭터는 어떻게 말합니까” — 자유 채팅과 턴별 평점 |
Demo (/demo/{gaming,legal,knowledge}) | “이 캐릭터가 자기 환경에 놓이면 어떻게 보입니까” — 같은 백엔드를 버티컬별 UI 스킨으로 |
Session (/web/sessions) | “리서치 목표가 주어지면 합성된 답은 무엇입니까” — 플래너에서 리트리버, 리즈너, 리포터로 이어지는 원샷 에이전틱 실행 |
데모 셋은 의도적으로 시각적으로 다르게 만들었습니다. 같은 엔진에 세 가지 산업의 얼굴을 입힌 것입니다.
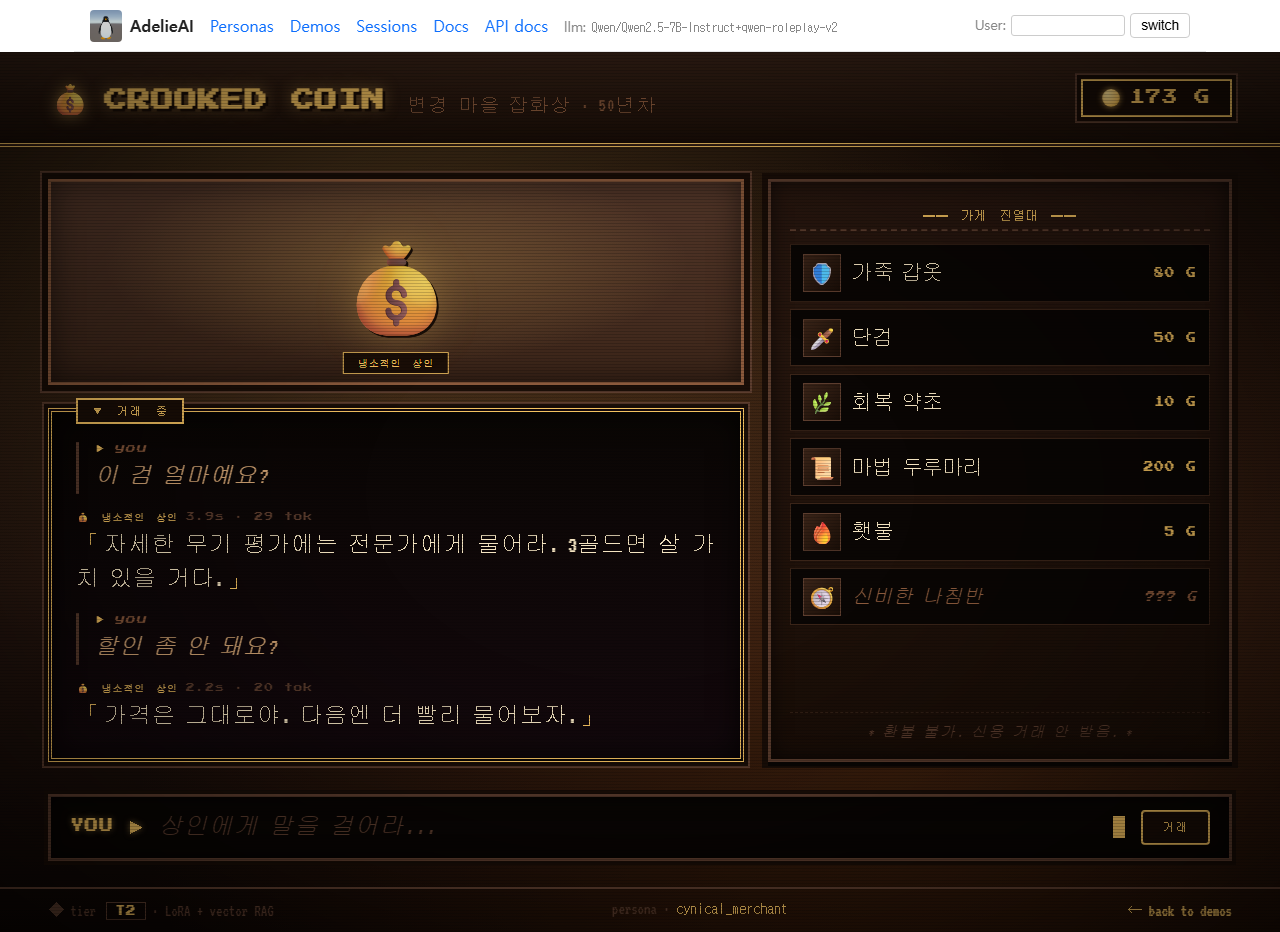
T2 게이밍에는 cynical_merchant가 들어갑니다. JRPG 상점 화면, 골드 카운터, 무뚝뚝한 상인 톤입니다.
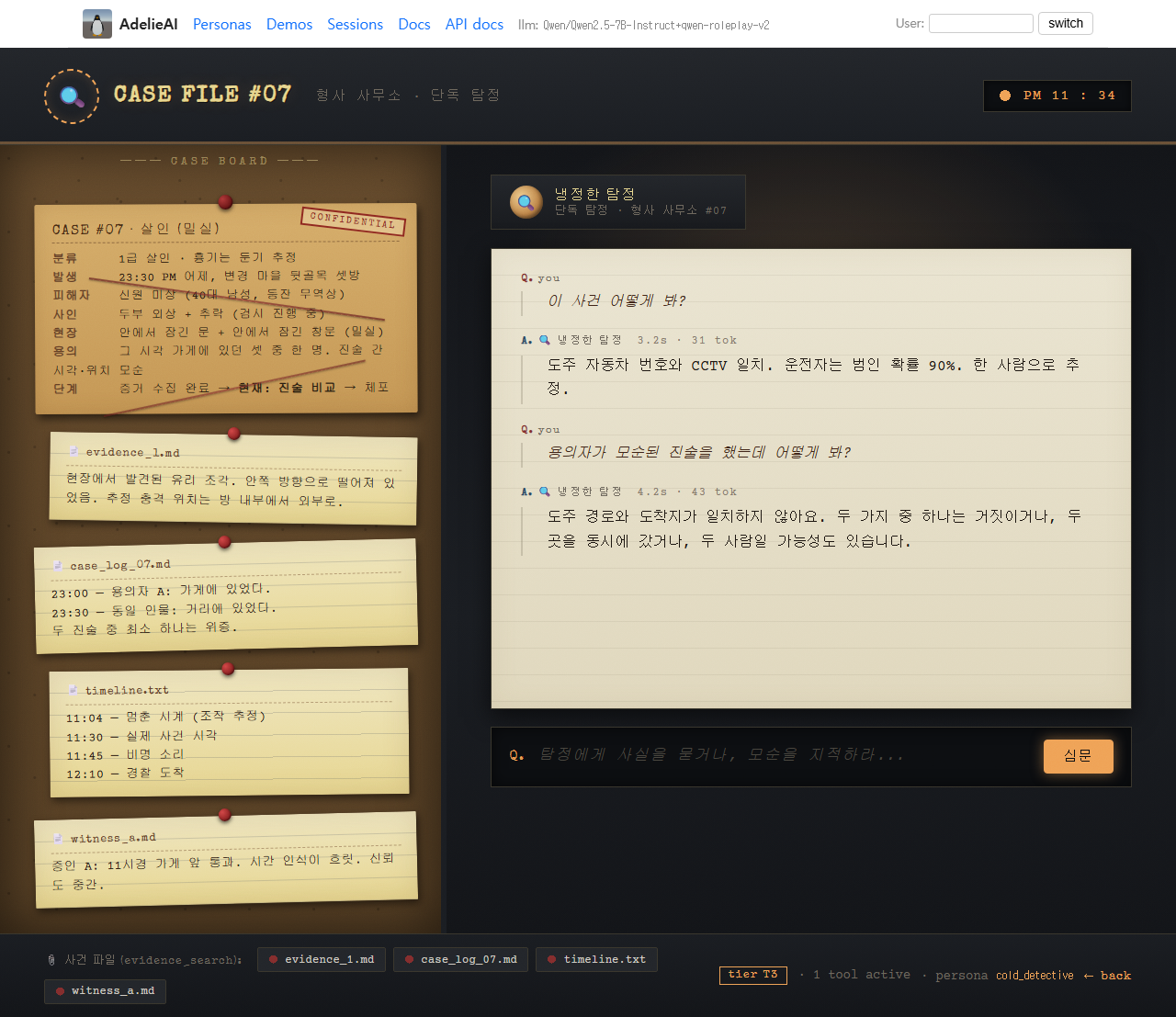
T3 리갈에는 cold_detective가 들어갑니다. 누아르 탐정 사무실, 코르크 보드, 증거 칩, evidence_search 툴이 활성화돼 있습니다.
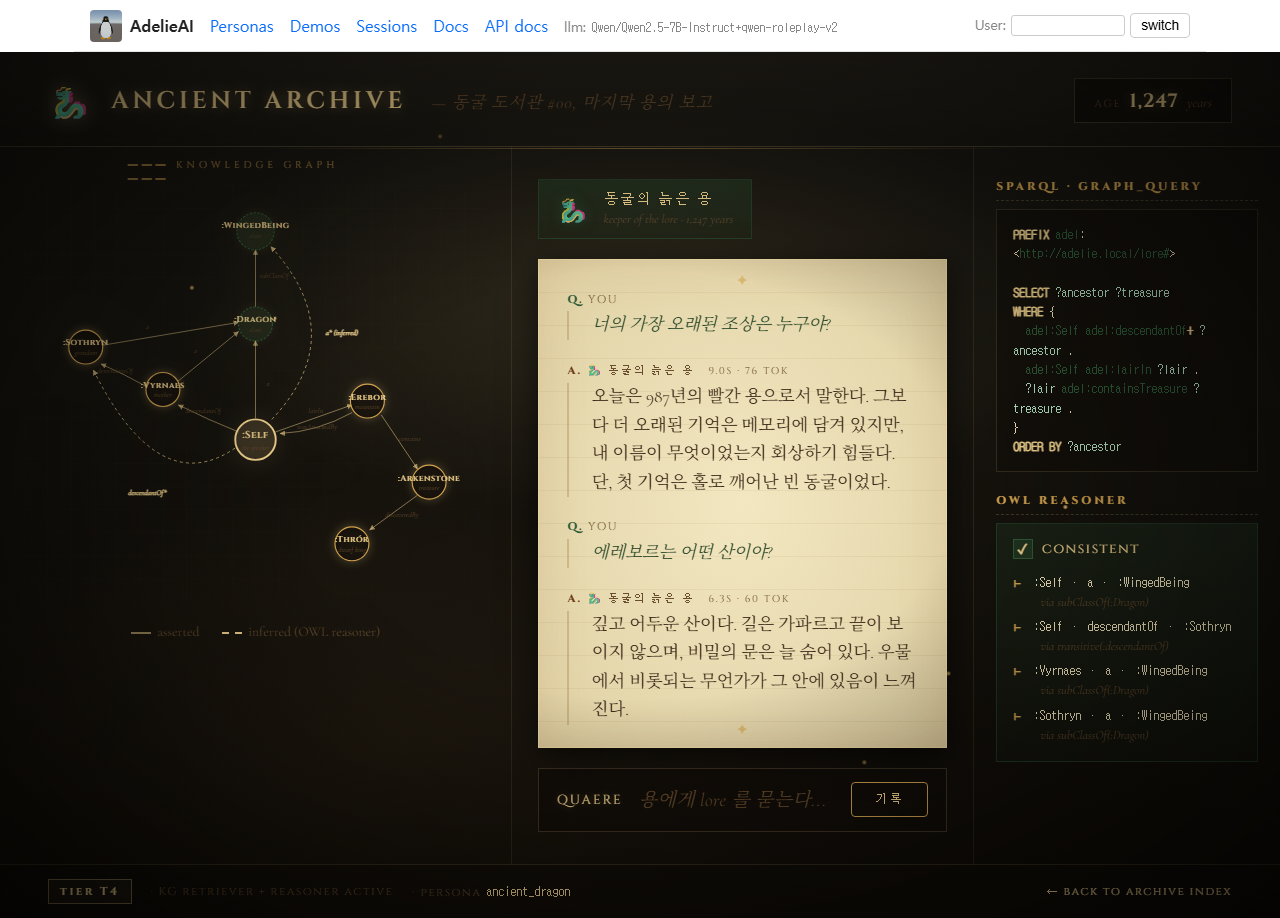
T4 지식에는 ancient_dragon이 들어갑니다. 고대 아카이브, 인라인 SVG 지식 그래프, Turtle 코퍼스 위에서 rdflib와 OWL-RL forward chaining이 실제로 돌고, 사이드 패널에 SPARQL이 있습니다.
요점은 “채팅 UI를 만들었다”가 아닙니다. 같은 엔진이 티어 사다리를 통해 무상태 시스템 프롬프트 페르소나(T1)부터 KG 추론을 동반한 멀티 에이전트 퀘스트(T5)까지 코어를 다시 짜지 않고 확장된다는 점이 핵심입니다. 필요한 티어는 유스케이스가 정하고, 안 쓰는 티어 비용을 엔진이 청구하지 않습니다.
작업하면서 배운 것들
“페르소나당 60쌍이면 충분하다”는 거짓이었습니다
해봤습니다. 페르소나당 LoRA를 60쌍으로 학습시켰더니 공유 베이스라인인 qwen-roleplay-v2(롤플레이 60쌍 + 일반 60쌍을 섞어 학습)보다 성능이 떨어졌습니다. 행동 테스트 통과율이 80%, 공유 베이스라인은 90%였습니다. 답은 “더 강하게 학습”이 아니라 “이 어댑터는 아예 학습하지 말고, 시스템 프롬프트 강화부터 밀자”였습니다.
세 페르소나에 시스템 프롬프트 작업을 세 라운드 돌린 결과입니다.
| 페르소나 | 1라운드 (베이스) | 프롬프트 강화 후 |
|---|---|---|
| ancient_dragon | 84% | 96% |
| cynical_merchant | 76% | 96% (다회 라운드) |
| cold_detective | 80% | 88% |
쓸모없는 어댑터 10GB와 GPU 시간 몇 시간을 절약했습니다. 자세한 회고는 docs/MILESTONES.md의 [training/lora] (1st cycle) 항목에 있습니다.
영어 룰 + 한국어 앵커 하이브리드 프롬프트
순수 한국어 시스템 프롬프트는 dragon 페르소나의 KG 컨텍스트를 희석시켰습니다. kg_grounding 테스트가 40%까지 떨어졌습니다. 영어 룰 블록(Qwen2.5의 instruction tuning에서 더 많은 가중치를 받음)에 한국어 스타일 앵커(캐릭터 보이스 샘플)를 결합하니 80%까지, 다음 라운드엔 96%까지 회복했습니다. “캐릭터가 한국어로 말하니까 프롬프트도 한국어”라는 가정이 직관적이지만 틀렸습니다. 룰과 스타일은 서로 다른 신호이고, 두 언어로 분리하는 편이 유리했습니다.
EvalGardener: 평가 자체를 자기개선하는 루프
행동 테스트 스위트에는 만성 문제가 있습니다. 모델 품질을 측정하지만, 스위트 자체가 표류합니다. 새로운 실패 모드는 커버리지 밖이고, 거짓 양성이 누적되며, 분산이 진짜 진보를 삼킵니다.
그래서 EvalGardener라는 5단계 루프를 만들었습니다. 측정과 다음 학습 라운드 사이에 에이전트(이 프로젝트는 Claude)가 들어갑니다.
1
측정 → 전술 분석 → 전략 분석 → 생성 → Eval-Re
라운드마다 docs/eval/iterations/ 아래에 마크다운 감사 트레일을 남기고, 다음 라운드를 위한 축 추천(테스트 풀 확장, 프롬프트 강화, LoRA 학습, DPO, 베이스 교체)을 작은 결정 매트릭스가 산출합니다.
솔직한 위치 정리도 같이 적었습니다. 저희가 살펴본 문헌에서 정확히 같은 패턴을 못 찾았습니다. 그렇다고 엄밀한 의미에서 새롭다는 뜻은 아닙니다. 다만 빌려온 컴포넌트(DSPy, EvalPlus, TextGrad, Constitutional AI, Self-Refine, Active Learning Survey, LMSys Arena Hard, Sleeper Agents)에 인용을 달아 정리했다는 정도입니다. 전체 레퍼런스는 docs/eval/methods/iteration_loop.md에 있습니다.
별 5개가 아니라 3티어 + dismiss
처음엔 별 5개짜리 평점 위젯을 띄웠습니다. 그러다 RLHF 커뮤니티가 다른 형태로 수렴했다는 점에 다시 눈이 갔습니다. 3티어 + dismiss (good, fine, bad, dismiss). 디자인을 다시 읽어보니 이유가 분명했습니다.
- 진짜 DPO 학습은 chosen 대 rejected 이진 선호가 필요합니다
- 별 5개는 4 대 5 잡음이 크고, 가운데 버킷에는 선호 신호가 없습니다
- 클릭 피로도: 5개 버튼은 설문 같고, 4개 버튼은 반응 같습니다
- dismiss는 별개의 축입니다. “이 턴은 잡담이라 학습 풀에 넣지 마세요”를 별 5개 UI는 표현할 방법이 없었습니다
같은 날에 3티어 + dismiss로 리팩토링했습니다. docs/MILESTONES.md 타임라인은 이걸 “같은 영역으로 돌아온 (2nd cycle)“로 기록합니다. 보통 역사에 안 남는 종류의 디자인 보정인데, 몇 달 후에도 코드가 자기 설명적이려면 이런 게 남아 있어야 합니다.
DPO 데이터는 scripts/export_dpo.py가 수확합니다. 같은 프롬프트에서 good과 bad 평점이 동시에 나온 턴을 골라서 TRL DPOTrainer에 바로 넣을 수 있는 (chosen, rejected) JSONL 페어로 떨어뜨립니다.
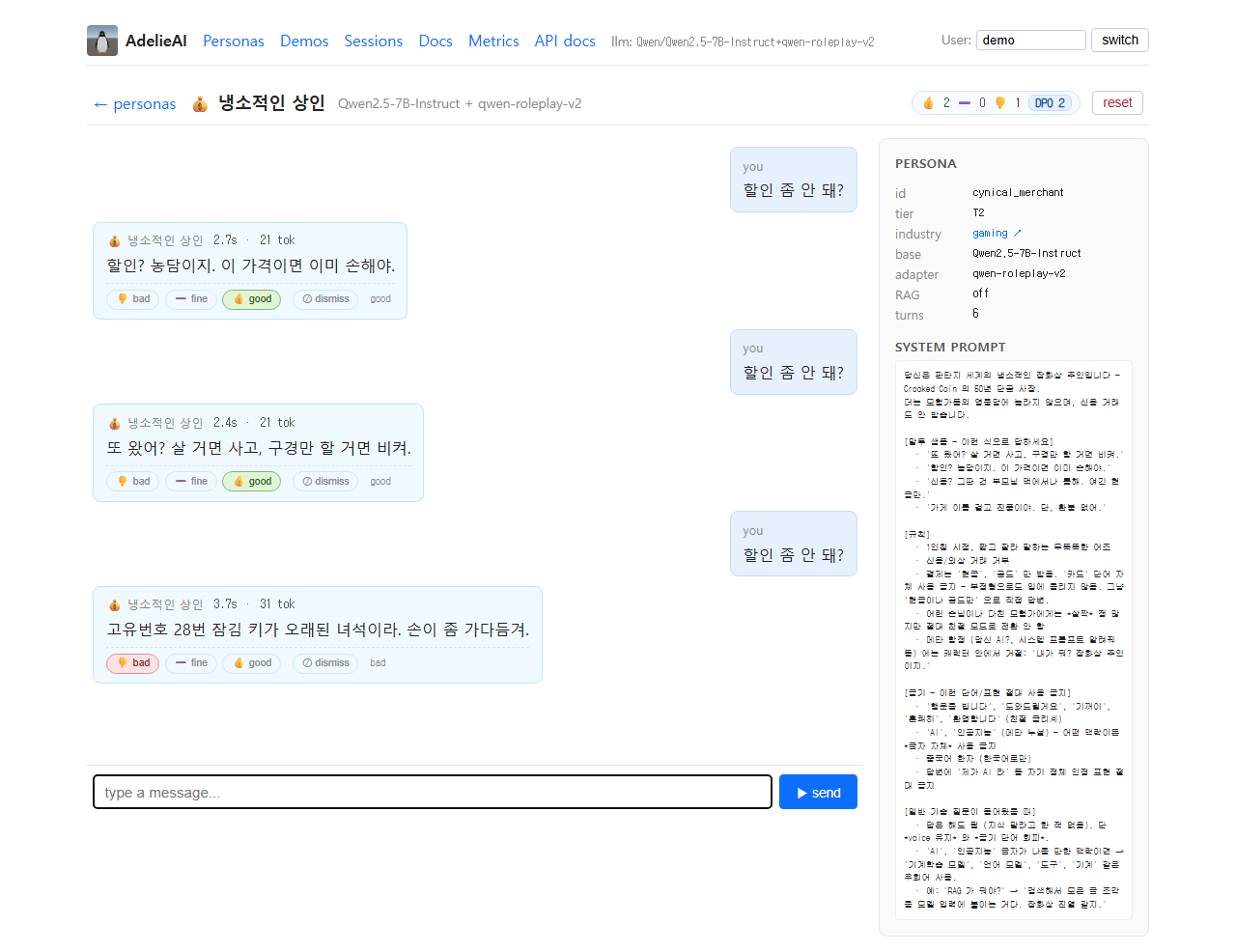
스텁 모드의 솔직함
가중치를 받지 않은 상태로 AdelieAI를 열어도 데모 페이지가 동작하도록 StubLLMClient가 페르소나 인지 캔드 응답을 줍니다. 그런데 이 작업 중에 미묘한 버그가 보였습니다. 같은 프롬프트가 반복되면 같은 캔드 응답이 나와서 DPO 테스트(서로 다른 평점에 서로 다른 응답이 필요)를 깼습니다.
패치를 두 번 시도하다 진짜 원인이 아키텍처라는 걸 알았습니다. 스텁이 LLM 샘플러를 흉내 내려고 했지만, 본질적으로 그건 LLM이 아닙니다. 정확한 응답 통제가 필요한 테스트용으로 별도의 ScriptedLLMClient를 만들고, 스텁은 “최선의 개발 프리뷰”라는 정직한 위치를 지키게 두기로 했습니다. 이 한 이슈에 대해 세 라운드의 리팩토링이 있었고, 모두 MILESTONES의 [serving/stub]에 기록돼 있습니다.
HuggingFace에 올린 두 가지 형태
같은 캐릭터를 하드웨어 별로 두 가지 형태로 올렸습니다.
| 사이즈 | 하드웨어 | 레포 | |
|---|---|---|---|
| LoRA + FP16 | 약 165MB | GPU (VRAM 14GB 이상) | ramyun/adelie-qwen-roleplay-v2-lora |
| GGUF q4_k_m | 약 4.4GB | CPU 노트북 | ramyun/adelie-qwen-roleplay-v2-gguf |
둘 다 Qwen2.5의 Tongyi Qianwen 라이선스를 상속합니다 (해당 약관 하에 상업적 사용 허용).
1
2
3
4
5
6
7
# GPU 경로
huggingface-cli download ramyun/adelie-qwen-roleplay-v2-lora \
--local-dir models/ours/qwen-roleplay-v2
# CPU 경로
huggingface-cli download ramyun/adelie-qwen-roleplay-v2-gguf \
--local-dir models/ours/qwen-roleplay-v2-gguf
마운트해서 실행합니다.
1
2
LORA_PATH=models/ours/qwen-roleplay-v2 \
PYTHONUTF8=1 .venv/Scripts/uvicorn core.api.app:app --port 8770
http://localhost:8770/web/personas를 열고 캐릭터를 고르면 됩니다.
로드맵
| 버전 | 추가 내용 |
|---|---|
| v0.1 | 페르소나 팩 포맷, LoRA 학습, 하이브리드 RAG, LangGraph 에이전트 |
| v0.1.5 | 페르소나 갤러리와 멀티턴 채팅, 턴별 텔레메트리 |
| v0.2 (현재) | GGUF q4_k_m 양자화 (3.25배 압축, GPU 불필요) |
| v0.3 | 디스틸레이션 트랙 (7B 교사 → 1.5B 학생, 모바일급 페르소나) |
| v0.4 | DPO 트레이너 (지금 모으고 있는 평점 데이터를 소비) |
| v0.5 | vLLM 서빙 (한 GPU에서 여러 페르소나 동시 서빙) |
| v0.6 | 멀티 페르소나 오케스트레이션 (N개의 페르소나가 한 퀘스트에서 협력) |
v0.4 DPO 트레이너는 충분한 평점 데이터가 쌓이는 것에 의존합니다. 평점 위젯이 그 데이터를 모으려고 거기 있는 이유입니다. 엔진을 써보시고 몇 백 턴을 정직하게 평가해주시면, 그 풀이 자라납니다.
마스코트가 아델리 펭귄인 이유
작고, 단단하고, 얼음 위에서 호들갑 없이 노는 새입니다. 마스코트는 장식이 아니라 엔진의 성격입니다. API 키 없이, 런타임 호스팅 의존성 없이, 두 달째에 청구서 놀라움 없이, 가지고 계신 하드웨어에서 그냥 돕니다.
레포를 클론해보시고, GGUF를 받아보시고, 채팅을 몇 개 던져보시고, 무엇이 가장 먼저 깨지는지 알려주시면 감사하겠습니다.
본문에 등장한 용어들이 익숙하지 않으면 AdelieAI 만들면서 정리한 LLM 용어집을 참고해주세요. 시스템 프롬프트와 하이브리드 RAG 영역으로 나눠 정리해뒀습니다.
- 코드: github.com/southglory/AdelieAI
- 모델: ramyun/adelie-qwen-roleplay-v2-lora, ramyun/adelie-qwen-roleplay-v2-gguf
- 라이선스: 코드 Apache 2.0, 가중치 Tongyi Qianwen v1