Python 자연어처리 형태소, 구문 분석(Syntactic Parsing)하기 with konlpy, spacy

학창시절 영어를 배울 때 참 문법을 많이 배웠었죠?
명사, 동사, 형용사, 부사,
관계대명사, 지시대명사, 인칭대명사,
주어 + 동사 + 목적어 구문 등등…
그런데 제가 왜 지금 이걸 다루느냐 하면…
동영상 자막을 자동으로 넣고 싶은데 적당히 어디서 끊어야 할지 자연어처리로 해결하려고 하기 때문입니당~
(사실 배우다보니 이런게 있는 걸 알게되고 그래서 역으로 적용 아이디어가 떠오른 거긴 합니다 ㅎㅎ 어쨌든~)
python은 참 편리합니다.
이번에는 python에서 오픈소스 라이브러리인 konlpy와 spacy를 각각 사용해서 구문 분석을 해보고, 어느 것이 더 결과가 좋은지 살짝만 비교해보겠습니다.
1. konlpy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import nltk
from konlpy.tag import Okt
# 형태소 분석기 객체 생성 (기존 Twitter() → Okt()로 변경)
okt = Okt()
# 형태소 분석 수행
sentence = "만 6세 이하의 초등학교 취학 전 자녀를 양육하기 위해서는"
words = okt.pos(sentence)
# 구문 분석을 위한 문법 정의
grammar = """
NP: {*?} # 명사구 (Noun Phrase)
VP: {*} # 동사구 (Verb Phrase)
AP: {*} # 형용사구 (Adjective Phrase)
"""
parser = nltk.RegexpParser(grammar)
chunks = parser.parse(words)
# 결과 출력
print("# 전체 구문 트리 출력")
print(chunks.pprint())
print("\n# 명사구(NP)만 출력")
for subtree in chunks.subtrees():
if subtree.label() == "NP":
print(" ".join((word for word, pos in subtree.leaves())))
print(subtree.pprint())
# 트리 시각화
chunks.draw()
## "위"가 단독으로 명사구(NP)로 분리되고, "해서는"이 동사구(VP)로 따로 떨어지는 문제 발생 😢
## -> 정교한 의존 구문 분석을 위해 Spacy 같은 NLP 라이브러리를 사용할 수도 있음.

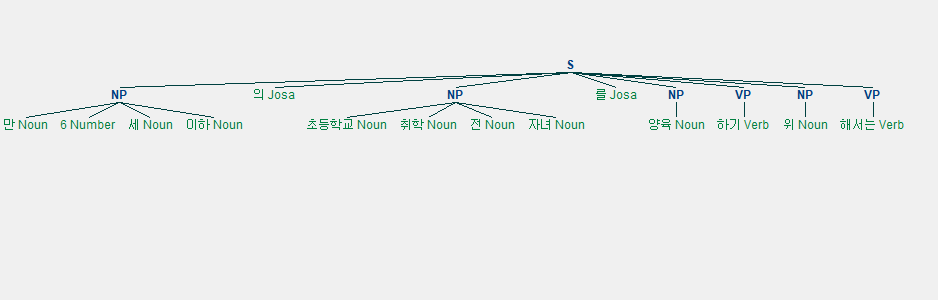
“위해서는” -> “위” + “해서는” 으로 나눠진 점이 아쉽네요~
2. spacy
1
2
3
4
5
6
7
8
9
10
11
import spacy
# python -m spacy download ko_core_news_sm
nlp = spacy.load("ko_core_news_sm") # 한국어 모델 로드
text = "만 6세 이하의 초등학교 취학 전 자녀를 양육하기 위해서는"
doc = nlp(text)
for token in doc:
print(token.text, [token.dep_, token.head.text])
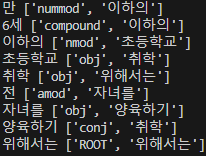
이거는 더 잘 된 것 같습니다!
konlpy 가 위 상황에서는 성능이 안좋았지만, 그래도 많이 쓰이는 오픈소스 패키지 답게 편리한 기능들이 많이 있습니다.
다음처럼 문장으로 나누거나, 명사만 뽑아내거나 하는 형태소 분석 코드를 쉽게 작성할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
from konlpy.tag import Kkma
from konlpy.utils import pprint
if __name__ == "__main__":
kkma = Kkma()
pprint(kkma.sentences("네, 안녕하세요. 반갑습니다."))
pprint(kkma.nouns("질문이나 건의사항은 깃헙 이슈 트래커에 남겨주세요."))
pprint(kkma.pos("오류보고는 실행환경, 에러메세지와함께 설명을 최대한상세히!^^"))
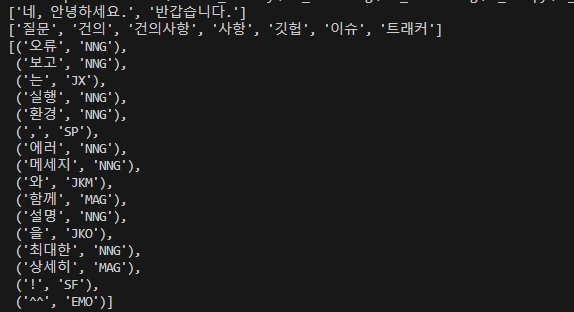
아주 유용합니다~

https://github.com/konlpy/konlpy/tree/master
GitHub - konlpy/konlpy: Python package for Korean natural language processing. Python package for Korean natural language processing. - konlpy/konlpy Python package for Korean natural language processing. - konlpy/konlpy
https://konlpy.org/ko/latest/examples/chunking/
혹시 오픈소스 패키지 별 속도 성능이 궁금하시다면, … https://konlpy.org/ko/latest/morph/#comparison-between-pos-tagging-classes
형태소 분석이 더 궁금하시다면… https://coding-yesung.tistory.com/200
- 자연어란 ❓ 일상에서 사용하는 언어 컴퓨터는 자연어를 직접적으로 이해할 수 없음 ➡ 컴퓨터가 자연어의 의미를 분석해 처리할 수 있도록 하는 일을 “자연어 처리(Natural Language Processing)” 2. 토크나이징 문장을 의미가 있는 가장 작은 단어들로 나움 나눠진 단어들을 이용해 의미를 분석 가장 기본이 되는 단어들을 '토큰'이라고 부름 문장 형태의 데이터를 처리하기 위해 제일 처음 수행해야 하는 기본적인 작업 토크나이징을 어떻게 하느냐에 따라 성능의 차이가 날 수 있음 3. 형태소 분석 자연어의 문장을 형태소…