RAG 연습 (1)
 출처: 국가법령정보 공동활용
출처: 국가법령정보 공동활용
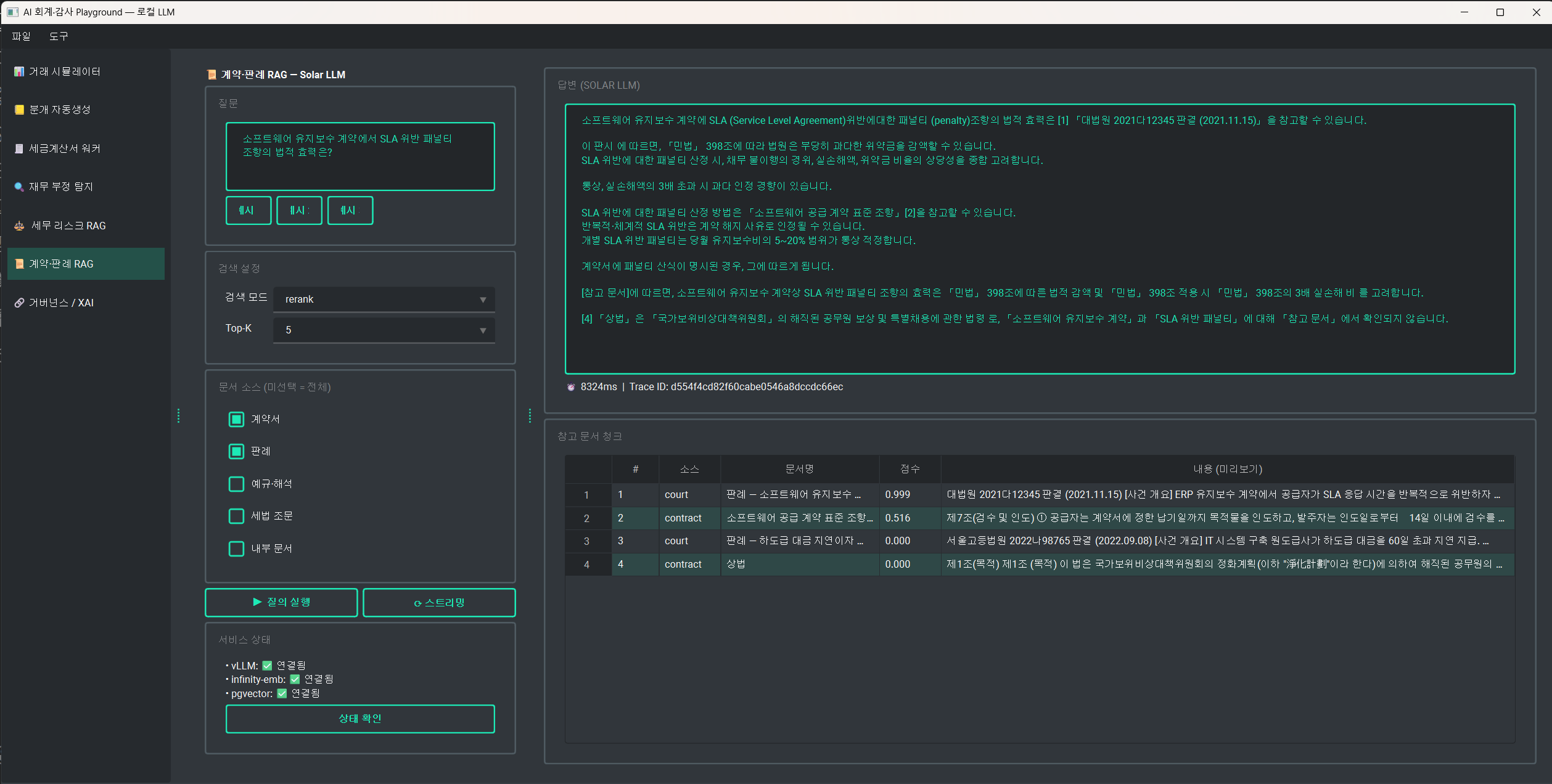
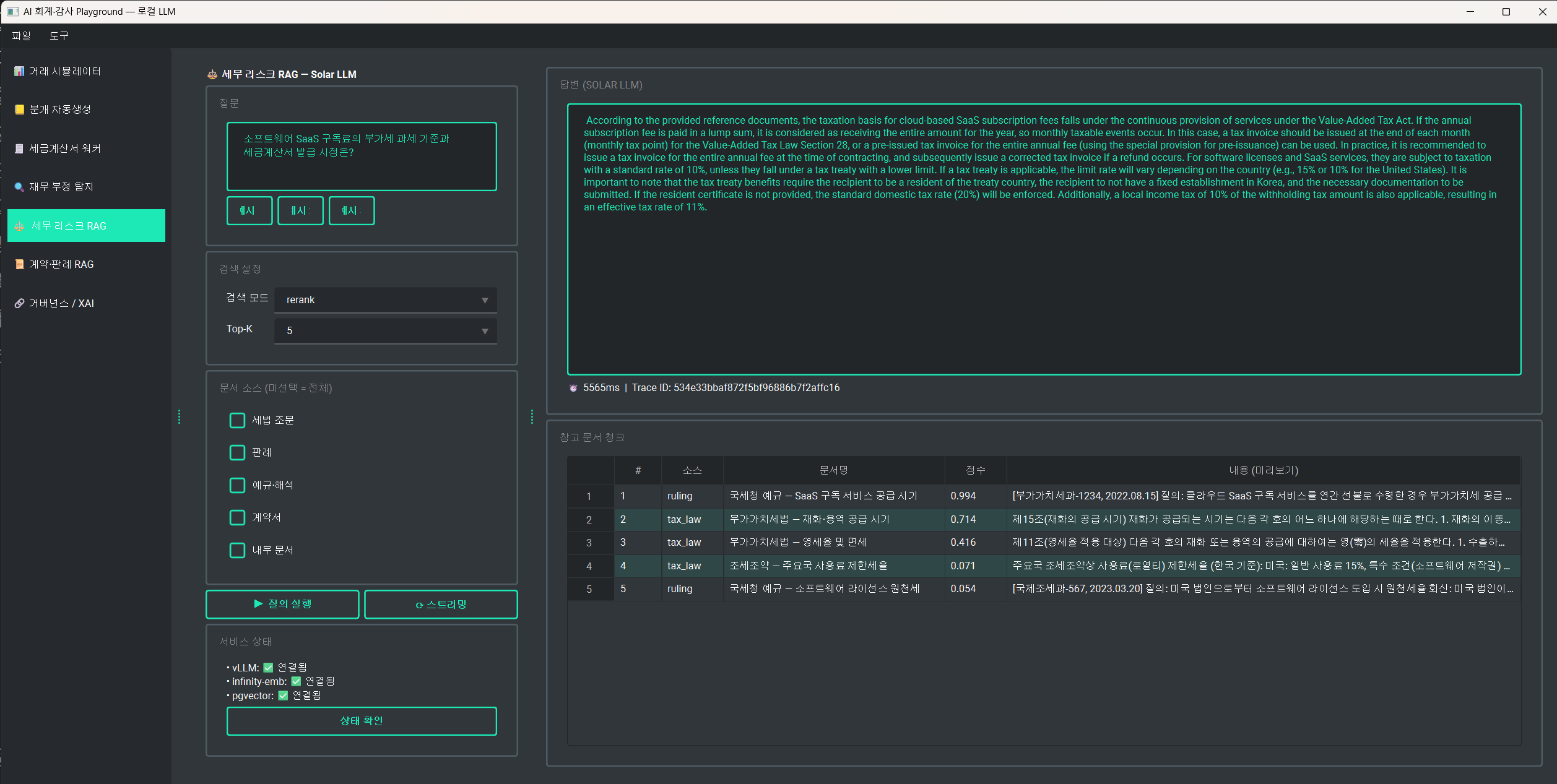
스택
여기선 LangChain/LlamaIndex 같은 RAG 프레임워크는 쓰지 않았습니다.
검색 → 프롬프트 조립 → LLM 호출은 core/rag/pipeline.py에서 직접 구현되었습니다.
| 역할 | 사용한 것 |
|---|---|
| 임베딩 서버 | infinity-emb (BGE-M3) |
| 리랭커 | infinity-emb (bge-reranker-v2-m3) |
| 벡터 DB | pgvector (PostgreSQL 확장) |
| LLM | vLLM (Solar-10.7B) |
| 파이프라인 | 직접 작성 (core/rag/pipeline.py) |
| 트레이싱 | Langfuse |
직접 구현한 이유
내부 동작을 설명할 수 있습니다. LangChain을 쓰면 “추상화 레이어 위에 얹었습니다”가 되지만, 직접 짜면 청킹 → 임베딩 배치 처리 → pgvector HNSW 검색 → 리랭킹 → 프롬프트 조립 전 과정을 코드로 설명할 수 있습니다.
의존성이 단순합니다. LangChain은 버전 업데이트가 잦고 내부 추상화가 복잡해서 디버깅이 어렵습니다. 지금 구조는 HTTP 클라이언트 + asyncpg + asyncio가 전부라 오류 추적이 명확합니다.
스택 교체가 쉽습니다. Provider 추상화(LLMProvider, EmbeddingProvider)가 돼 있어서 vLLM → Upstage API, infinity-emb → 다른 임베딩 서버로 바꿔도 어댑터 하나만 교체하면 됩니다.
단점과 프레임워크 도입 시점
LangGraph 같은 걸 쓰면 멀티에이전트 분기, 재시도, 상태 관리를 무료로 얻는데 지금은 그게 없습니다. 복잡한 에이전트 워크플로우로 확장할 때 직접 구현의 비용이 올라갑니다.
그래서 도입을 고려하는 시점은 두 가지입니다.
멀티스텝 추론이 필요할 때. “이 거래의 세무 리스크를 분석해줘”가 거래 데이터 조회 → 세무 RAG 검색 → 리스크 판단 → 위험 시 관련 판례 추가 검색 → 보고서 생성 같은 조건 분기와 루프가 생길 때.
에이전트가 2개 이상 협업할 때. 재무 부정 탐지 에이전트, 세무 리스크 에이전트, 보고서 생성 에이전트가 서로 결과를 넘기는 구조가 될 때.
(클로드 코드의 도움을 받았습니다.)