물리 현상 예측 모델 훈련하기_ 기본적인 문제부터
예전에 만들었던 3D 로또추첨앱에서 넣지 못했던 인공지능 기능을 더 생각해보았습니다.
https://blog.naver.com/devramyun/223350564515
[20240211] 로또번호 뽑기 생성기 - 에어브레스 업데이트 릴리즈50 https://play.google.com/store/apps/details?id=com.QUIRKAGAMES.SpecialLotto645 제… https://play.google.com/store/apps/details?id=com.QUIRKAGAMES.SpecialLotto645 제…
저의 앱은 실제 로또추첨 기기(비너스 로또 추첨 기기)를 모방해서 공기 흐름으로 공을 추첨하는 방식이었는데,
https://blog.naver.com/devramyun/223209598619
[20230914] making Ball drawing machine(9월~10월 프로젝트, 구글 앱스토어 출시 완료) https://youtu.be/VEwMA80nGp4 ball spec 밀도:8g/cc 동일한 밀도를 가지는 폴리우레탄(PU)의 물성… https://youtu.be/VEwMA80nGp4 ball spec 밀도:8g/cc 동일한 밀도를 가지는 폴리우레탄(PU)의 물성…
기기의 가속도 센서의 값에 따라 앱 내 중력 방향이 변하도록 해서 뽑기의 변수를 주는 형식이었습니다.
그래서 이 앱은 사용자의 조작에 따른 운을 시험할 수 있는 추첨 앱이었습니다.
그렇다면 물리적 현상을 수치적 모델로 모사해서 그 모델에서 추첨하도록 하는 방식으로 하면 어떨까? 하는 생각으로 더 나아갈 수가 있습니다. 저는 대학에서 기계공학을 공부할 적에 부식이라는 물리적 현상의 수치값 확률을 모사하는 간단한 모델 파라미터를 추정한 적이 있습니다. 그 과정의 신뢰도를 떠나서, 일단 물리적 현상을 수치적 분포 모델에 모사하려는 시도를 했다는 점에 있어서 저에게 의미가 있는 연구였는데요, 이번에도 그렇게 할 수 있지 않을까 하는 마음을 가지고 있었습니다.
물리적 현상이 비결정적으로 보이지만, 그 안에 수 많은 변수로 확장해서 보면 얼추 결정적인 문제가 될 수도 있습니다. 예를 들어 물체를 던질 때 어디에 떨어질지를 계산할 때 공기저항을 무시하고 중력가속도를 고정하고 초기 속도와 위치를 안다고 가정한다면 어디까지 날아가서 떨이질 지 계산이 가능하듯 말입니다.
그리고 물리적 현상을 특정 모델의 파라미터에 맞추려고 하기보단, 인공지능 모델에 학습시키는 편이 더 좋은 방법입니다. 왜냐하면 제가 풀고 싶은 문제는 고정된 문제가 아니라 점진적으로 변수, 차원을 추가해서 심화시켜야 하는 문제이기 때문입니다. 그렇게 다양한 일반화된 모델을 원하기 때문에 고정파라미터를 가지는 수치적 모델로는 차원을 점점 높이면 제대로 사용할 수가 없게 됩니다.
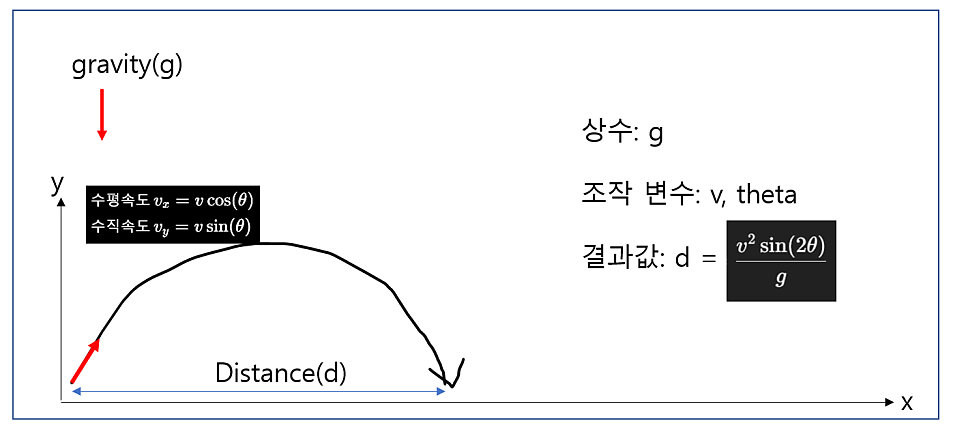
1번째로 정의해본 문제입니다. 조작변수 2개에 의해 결과값인 거리(d)를 예측하는 문제입니다.
포물선 운동의 수평 이동 거리를 예측하기 위해 다층 퍼셉트론(MLP) 모델을 사용하였습니다.
- 모델 임포트
1
2
3
4
import numpy as np
from sklearn.neural_network import MLPRegressor
from sklearn.model_selection import train_test_split, KFold, cross_val_score
import matplotlib.pyplot as plt
- 데이터 생성
1
2
3
4
5
6
7
8
9
10
11
def generate_data(n_samples=1000):
np.random.seed(42) # 랜덤 시드 설정
v = np.random.uniform(5, 50, n_samples) # 속도 v (5m/s에서 50m/s)
theta = np.radians(np.random.uniform(5, 85, n_samples)) # 발사각 theta (5도에서 85도)
g = 9.81 # 중력 가속도 m/s^2
x_distance = (v**2) * np.sin(2 * theta) / g # 수평 이동 거리 계산
# 입력 변수와 출력 변수
X = np.column_stack((v, theta))
y = x_distance
return X, y
- 모델 설정 및 교차검증
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 데이터 생성
X, y = generate_data(1000)
# 교차 검증 설정
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 모델 설정
model = MLPRegressor(hidden_layer_sizes=(50,), max_iter=1000, activation='relu', solver='adam', random_state=42)
# 교차 검증 수행
cv_scores = cross_val_score(model, X, y, cv=kf, scoring='neg_mean_squared_error')
# MSE 출력
print("교차 검증 MSE: ", -cv_scores)
print("평균 MSE: ", -np.mean(cv_scores))
- 모델 훈련 및 평가
1
2
3
4
5
6
7
8
9
10
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 훈련
model.fit(X_train, y_train)
# 테스트 데이터에 대한 예측 및 평가
predictions = model.predict(X_test)
mse = np.mean((predictions - y_test)**2)
print("테스트 세트 MSE: ", mse)
얼마나 잘 맞추는지는 mean square error(mse)가 작은지를 보고 알 수 있습니다.
그런데 해놓고 보니 문제를 잘못 설정한 것 같습니다.
그래서 문제를 바꿔봅니다.
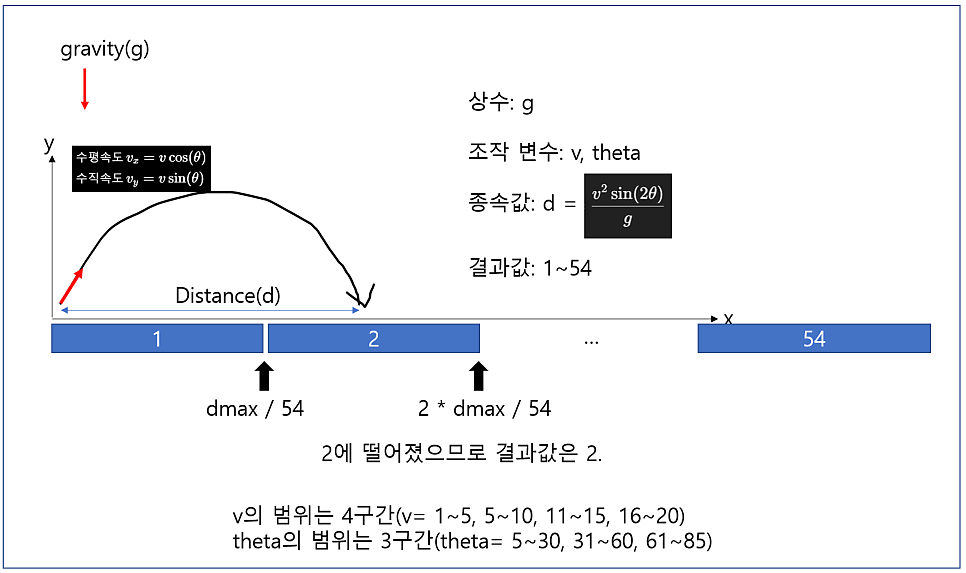
분류 문제로 바꾸기 위해 결과값 1부터 54까지 라벨을 만들었습니다. 그리고 구간을 나눴습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
import numpy as np
from sklearn.discriminant_analysis import StandardScaler
from sklearn.metrics import classification_report, f1_score
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
# 물리적 상수 설정
g = 9.81 # 중력 가속도 m/s^2
# 발사 속도(v)와 각도(theta)를 기반으로 던져진 물체의 수평 이동 거리를 계산하는 함수
def calculate_distance(v, theta):
theta_rad = np.radians(theta) # 각도를 라디안으로 변환
distance = (v ** 2) * np.sin(2 * theta_rad) / g
return distance
# v = 20, theta = 45 일 때 distance값을 max_distance로 설정할 수도 있지만, 문제 확장성을 위해 무작위 시행에 의한 최대값 산출을 통해 max_distance를 설정합니다.
max_distances = []
for _ in range(1000):
v = np.random.uniform(1, 20)
theta = np.random.uniform(5, 85)
max_distances.append(calculate_distance(v, theta))
max_distance = max(max_distances)
v_ranges = [(1, 5), (5, 10), (11, 15), (16, 20)]
theta_ranges = [(5, 30), (31, 60), (61, 85)]
# 각 범위 내에서 무작위로 값을 선택하여 데이터를 생성합니다.
# 또한 이동 거리(d)에 따른 결과값 레이블(1~54)을 생성합니다.
# 데이터와 레이블을 저장할 리스트를 초기화합니다.
data = []
labels = []
# 지정된 각 범위 내에서 v와 theta를 무작위로 선택하고, 각 조합에 대해 이동 거리(d)를 계산합니다.
for v_range in v_ranges:
for theta_range in theta_ranges:
for _ in range(3000): # 각 조합에 대해 동일한 수의 샘플을 생성합니다.
# v와 theta를 해당 범위 내에서 무작위로 선택합니다.
v = np.random.uniform(v_range[0], v_range[1])
theta = np.random.uniform(theta_range[0], theta_range[1])
# 이동 거리를 계산합니다.
distance = calculate_distance(v, theta)
# 결과 레이블을 생성합니다.
label = np.ceil((distance / max_distance) * 54)
# 데이터와 레이블을 리스트에 추가합니다.
data.append([v, theta])
labels.append(label)
# 데이터와 레이블을 NumPy 배열로 변환합니다.
X = np.array(data)
y = np.array(labels).flatten() # 레이블 배열을 1차원으로 변환합니다.
# 입력 데이터를 스케일링합니다.
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 훈련 및 테스트 데이터로 분할합니다.
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 새로운 다층 퍼셉트론 분류기를 생성합니다.
mlp = MLPClassifier(hidden_layer_sizes=(100,), activation='relu', max_iter=300, random_state=42)
# 모델을 훈련합니다.
mlp.fit(X_train, y_train)
# 테스트 데이터에 대한 예측을 수행합니다.
y_pred = mlp.predict(X_test)
# 새로운 F1 점수를 계산합니다.
f1 = f1_score(y_test, y_pred, average='weighted')
# 새로운 분류 리포트를 생성합니다.
report = classification_report(y_test, y_pred)
f1, report
가중 평균 F1 점수가 0.7692779375881951 이 나왔습니다.
살짝 아쉽네요.
모델의 hidden_layer_sizes를 높이면 더 성능이 올라갈 것 같습니다. 하지만 다른 방법으로 해봅니다.
dropout을 사용해달라고 gpt에게 부탁했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 새로운 다층 퍼셉트론 분류기를 생성합니다.
# 이번에는 각 은닉층 후에 드롭아웃을 추가하여 과적합을 방지합니다.
from sklearn.neural_network import MLPClassifier
# 모델을 정의합니다.
mlp_with_dropout = MLPClassifier(
hidden_layer_sizes=(100,), # 첫 번째 은닉층의 뉴런 수
activation='relu', # 활성화 함수
solver='adam', # 옵티마이저
max_iter=300, # 최대 반복 횟수
random_state=42, # 랜덤 시드
alpha=0.01 # L2 규제 강도
# dropout은 sklearn의 MLPClassifier에 직접 적용되지 않습니다.
# 대신 alpha 매개변수로 L2 규제를 사용할 수 있습니다.
# 복잡한 모델에서 dropout을 사용하고 싶다면 TensorFlow나 PyTorch와 같은 라이브러리를 사용해야 합니다.
)
# 모델을 훈련합니다.
mlp_with_dropout.fit(X_train, y_train)
# 테스트 데이터에 대한 예측을 수행합니다.
y_pred = mlp_with_dropout.predict(X_test)
# 새로운 F1 점수를 계산합니다.
f1 = f1_score(y_test, y_pred, average='weighted')
# 새로운 분류 리포트를 생성합니다.
report = classification_report(y_test, y_pred)
f1, report
sklearn 패키지의 MLPClassifier에는 dropout기능이 없기 때문에 대안으로 L2 규제 옵션을 적용했습니다.
그런데 가중평균 F1점수가 0.6836382402193353 로 오히려 낮아졌습니다.
그래서 sklearn과 이별하고 pytorch로 넘어가봅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.metrics import f1_score
from sklearn.preprocessing import StandardScaler
# PyTorch에서는 GPU를 사용할 수 있으므로 사용 가능한 경우 GPU를 설정합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 타깃 레이블을 0부터 54 범위에 있도록 최소값이 0이 되도록 조정합니다.
y_train = y_train - np.min(y_train)
y_test = y_test - np.min(y_test)
# 데이터셋을 PyTorch 텐서로 변환합니다.
X_train_tensor = torch.tensor(X_train).float().to(device)
y_train_tensor = torch.tensor(y_train).long().to(device) # CrossEntropyLoss를 사용하기 위해 long 타입으로 설정
X_test_tensor = torch.tensor(X_test).float().to(device)
y_test_tensor = torch.tensor(y_test).long().to(device)
# DataLoader를 생성합니다.
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
# 신경망 모델 정의, 출력층 크기를 클래스 수(55)로 설정
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2, 100) # 입력층
self.fc2 = nn.Linear(100, 100) # 은닉층
self.fc3 = nn.Linear(100, 55) # 출력층: 클래스가 0~54이므로 55개의 출력 필요
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.5) # 드롭아웃 적용
x = F.relu(self.fc2(x))
x = F.dropout(x, p=0.5) # 드롭아웃 적용
x = self.fc3(x)
return x
# 모델을 초기화하고 GPU로 이동(사용 가능한 경우)
model = Net().to(device)
# 손실 함수와 최적화 알고리즘 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 훈련 함수
def train(model, train_loader, optimizer, criterion):
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 모델 평가 함수
def evaluate(model, X_test, y_test):
model.eval()
with torch.no_grad():
output = model(X_test)
pred = output.argmax(dim=1, keepdim=True)
correct = pred.eq(y_test.view_as(pred)).sum().item()
f1 = f1_score(y_test.cpu(), pred.cpu(), average='weighted')
return correct / len(X_test), f1
# 훈련 과정
epochs = 500
for epoch in range(1, epochs + 1):
train(model, train_loader, optimizer, criterion)
test_accuracy, test_f1 = evaluate(model, X_test_tensor, y_test_tensor)
print(f'Epoch: {epoch}, Test accuracy: {test_accuracy:.4f}, Test F1 Score: {test_f1:.4f}')
# 최종 평가
final_accuracy, final_f1 = evaluate(model, X_test_tensor, y_test_tensor)
print(f'Final Test accuracy: {final_accuracy:.4f}, Final Test F1 Score: {final_f1:.4f}')
위의 코드를 보면 y 라벨데이터의 범위가 1부터 시작하는데, 훈련을 위해서는 0부터 시작해야하기 때문에 이동시켜줬습니다.
1
2
3
4
# 라벨의 개수 출력 결과 >> 55
print(len(np.unique(y)))
# 라벨의 최소값, 최대값 출력 결과 >> (1.0, 55.0)
np.min(y), np.max(y)
1
2
3
# 타깃 레이블을 0부터 54 범위에 있도록 최소값이 0이 되도록 조정합니다.
y_train = y_train - np.min(y_train)
y_test = y_test - np.min(y_test)
꽤 오래 했는데, 결과가 좋지 않았습니다.
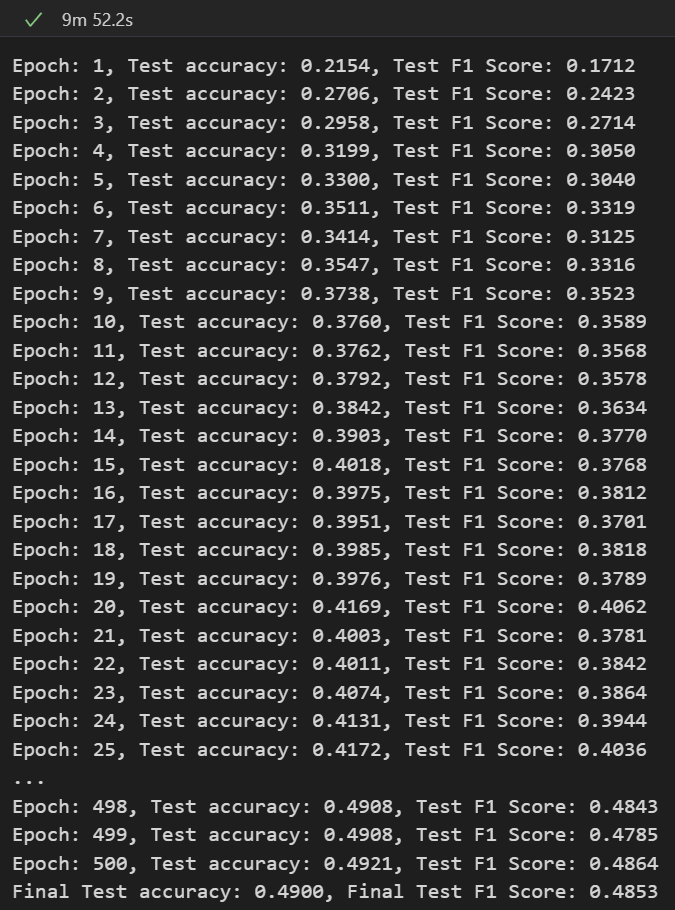
좀 더 다른 방법을 사용하던가, 아니면 잘 나왔던 첫 번째 MLPClassifier에서 layer 수를 늘려서 해보는 방법이 있을 것 같습니다.
그렇지만 여기서 문제를 한 번 더 바꿔봅니다.
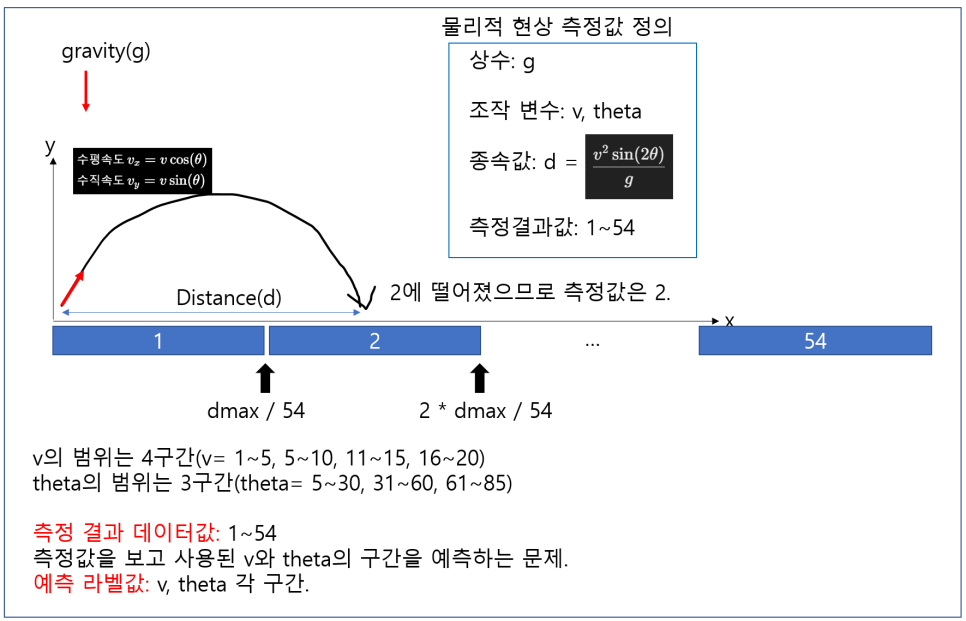
이제는 Multi - Label 문제입니다. 라벨이 여러개 입니다.
여기서부터는 다음 포스팅에서 하겠습니다.
감사합니다.
