물리 현상 예측 모델 훈련하기_ 기본적인 문제부터(2)
지난 포스팅에 이어서 진행하겠습니다. 지난 포스팅을 안 보신 분은 다음 링크의 포스팅을 먼저 읽어주세요.
https://blog.naver.com/devramyun/223418779972
[20240417] 물리 현상 예측 모델 훈련하기_ 기본적인 문제부터 예전에 만들었던 3D 로또추첨앱에서 넣지 못했던 인공지능 기능을 더 생각해보았습니다. https://blog.nav… 예전에 만들었던 3D 로또추첨앱에서 넣지 못했던 인공지능 기능을 더 생각해보았습니다. https://blog.nav…
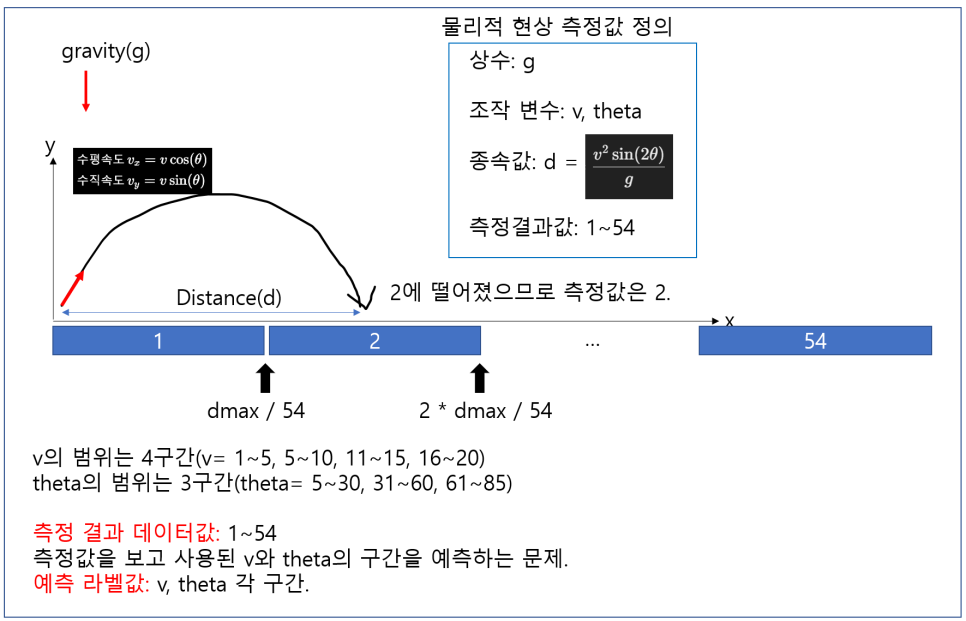
이번에는 멀티라벨을 예측하는 문제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 생성 및 전처리
def calculate_distance(v, theta):
g = 9.81 # 중력 가속도 m/s^2
theta_rad = np.radians(theta)
return (v ** 2) * np.sin(2 * theta_rad) / g
# v와 theta 구간 정의
# v는 v1부터 vmax까지 중 n개의 구간으로 나눈다.
# 인풋: N0, Nmax, n
def define_ranges(N0, Nmax, n):
ranges = []
for i in range(n):
N_range = (N0 + (Nmax - N0) / n * i, N0 + (Nmax - N0) / n * (i + 1))
ranges.append(N_range)
return ranges
v_ranges = define_ranges(1, 20, 4)
theta_ranges = define_ranges(5, 85, 3)
print(v_ranges)
print(theta_ranges)
# 데이터 생성
data = []
labels_v = []
labels_theta = []
for v_range in v_ranges:
for theta_range in theta_ranges:
for _ in range(300): # 각 조합에 대해 300개의 샘플을 생성
v = np.random.uniform(v_range[0], v_range[1])
theta = np.random.uniform(theta_range[0], theta_range[1])
distance = calculate_distance(v, theta)
data.append([distance]) # 이동 거리를 데이터로 사용
labels_v.append(v_ranges.index(v_range)) # v의 구간 인덱스
labels_theta.append(theta_ranges.index(theta_range)) # theta의 구간 인덱스
# 데이터를 NumPy 배열로 변환
X = np.array(data)
y_v = np.array(labels_v)
y_theta = np.array(labels_theta)
# 데이터 분할 및 스케일링
X_train, X_test, y_v_train, y_v_test, y_theta_train, y_theta_test = train_test_split(X, y_v, y_theta, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# PyTorch 텐서로 변환
X_train_tensor = torch.tensor(X_train_scaled).float()
y_v_train_tensor = torch.tensor(y_v_train).long()
y_theta_train_tensor = torch.tensor(y_theta_train).long()
X_test_tensor = torch.tensor(X_test_scaled).float()
y_v_test_tensor = torch.tensor(y_v_test).long()
y_theta_test_tensor = torch.tensor(y_theta_test).long()
# DataLoader 설정
train_dataset = TensorDataset(X_train_tensor, y_v_train_tensor, y_theta_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 신경망 모델 정의
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 100)
self.fc2 = nn.Linear(100, 100)
self.fc_v = nn.Linear(100, len(v_ranges)) # v 구간 예
self.fc_theta = nn.Linear(100, len(theta_ranges)) # theta 구간 예측
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.5)
x = F.relu(self.fc2(x))
x = F.dropout(x, p=0.5)
v_output = self.fc_v(x)
theta_output = self.fc_theta(x)
return v_output, theta_output
# 모델 인스턴스 생성
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
# 손실 함수 및 최적화기 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 훈련 함수
def train(model, train_loader, optimizer, criterion):
model.train()
total_loss = 0
for data, v_target, theta_target in train_loader:
data = data.to(device)
v_target = v_target.to(device)
theta_target = theta_target.to(device)
optimizer.zero_grad()
v_output, theta_output = model(data)
loss_v = criterion(v_output, v_target)
loss_theta = criterion(theta_output, theta_target)
loss = loss_v + loss_theta # 두 손실의 합
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
# 평가 함수
def evaluate(model, X_test, y_v_test, y_theta_test):
model.eval()
with torch.no_grad():
v_output, theta_output = model(X_test.to(device))
v_pred = torch.argmax(v_output, dim=1)
theta_pred = torch.argmax(theta_output, dim=1)
correct_v = (v_pred == y_v_test.to(device)).sum().item()
correct_theta = (theta_pred == y_theta_test.to(device)).sum().item()
total = len(X_test)
return (correct_v / total, correct_theta / total)
# 훈련 과정
epochs = 300
for epoch in range(1, epochs + 1):
loss = train(model, train_loader, optimizer, criterion)
v_accuracy, theta_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor)
if epoch % 10 == 0:
print(f'Epoch: {epoch}, Loss: {loss:.4f}, v Accuracy: {v_accuracy:.4f}, Theta Accuracy: {theta_accuracy:.4f}')
# 최종 평가
final_v_accuracy, final_theta_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor)
print(f'Final v Accuracy: {final_v_accuracy:.4f}, Final Theta Accuracy: {final_theta_accuracy:.4f}')
훈련은 금방 끝납니다.
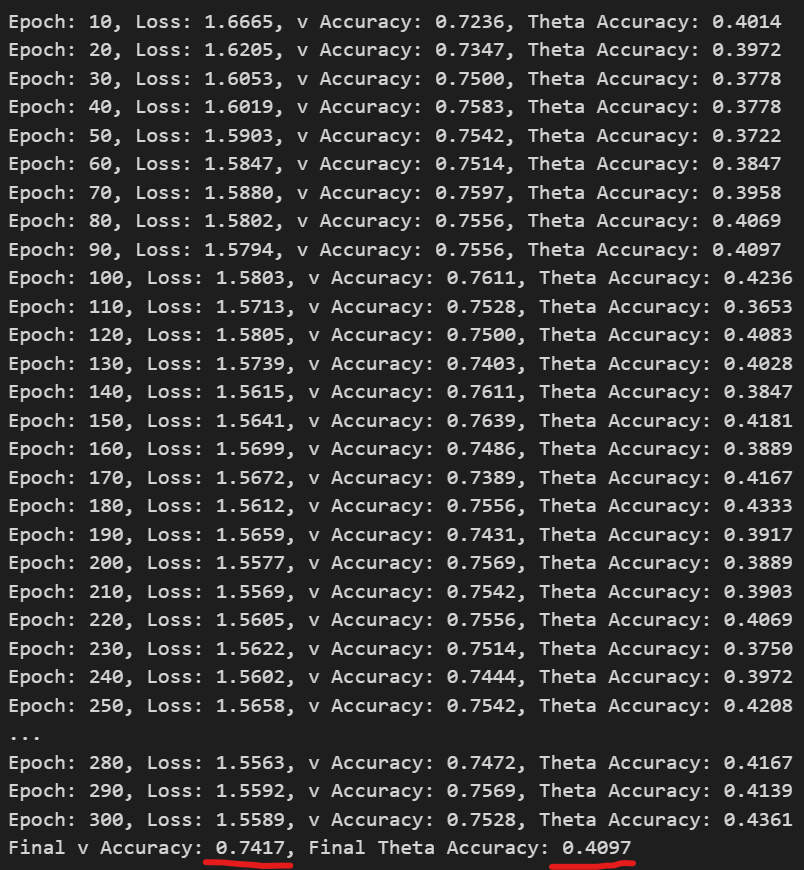
그런데 속도v 예측정확도는 70퍼센트 이상으로 높은 반면, 발사각도theta 예측 정확도는 40퍼센트로 매우 낮았습니다.
gpt에게 물어봤습니다.


(1번) 더 세밀한 구간 나누기 (4번) 특성 엔지니어링(파생변수 사용)
이렇게 두 제안을 받아들였습니다.
theta의 구간을 세밀하게 나눠서 다시 진행해봅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 생성 및 전처리
def calculate_distance(v, theta):
g = 9.81 # 중력 가속도 m/s^2
theta_rad = np.radians(theta)
return (v ** 2) * np.sin(2 * theta_rad) / g
# v와 theta 구간 정의
# v는 v1부터 vmax까지 중 n개의 구간으로 나눈다.
# 인풋: N0, Nmax, n
def define_ranges(N0, Nmax, n):
ranges = []
for i in range(n):
N_range = (N0 + (Nmax - N0) / n * i, N0 + (Nmax - N0) / n * (i + 1))
ranges.append(N_range)
return ranges
v_ranges = define_ranges(1, 20, 4)
theta_ranges = define_ranges(5, 85, 6)
print(v_ranges)
print(theta_ranges)
# 데이터 생성
data = []
labels_v = []
labels_theta = []
for v_range in v_ranges:
for theta_range in theta_ranges:
for _ in range(300): # 각 조합에 대해 300개의 샘플을 생성
v = np.random.uniform(v_range[0], v_range[1])
theta = np.random.uniform(theta_range[0], theta_range[1])
distance = calculate_distance(v, theta)
data.append([distance]) # 이동 거리를 데이터로 사용
labels_v.append(v_ranges.index(v_range)) # v의 구간 인덱스
labels_theta.append(theta_ranges.index(theta_range)) # theta의 구간 인덱스
# 데이터를 NumPy 배열로 변환
X = np.array(data)
y_v = np.array(labels_v)
y_theta = np.array(labels_theta)
# 데이터 분할 및 스케일링
X_train, X_test, y_v_train, y_v_test, y_theta_train, y_theta_test = train_test_split(X, y_v, y_theta, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# PyTorch 텐서로 변환
X_train_tensor = torch.tensor(X_train_scaled).float()
y_v_train_tensor = torch.tensor(y_v_train).long()
y_theta_train_tensor = torch.tensor(y_theta_train).long()
X_test_tensor = torch.tensor(X_test_scaled).float()
y_v_test_tensor = torch.tensor(y_v_test).long()
y_theta_test_tensor = torch.tensor(y_theta_test).long()
# DataLoader 설정
train_dataset = TensorDataset(X_train_tensor, y_v_train_tensor, y_theta_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 신경망 모델 정의
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 100)
self.fc2 = nn.Linear(100, 100)
self.fc_v = nn.Linear(100, len(v_ranges)) # v 구간 예
self.fc_theta = nn.Linear(100, len(theta_ranges)) # theta 구간 예측
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.5)
x = F.relu(self.fc2(x))
x = F.dropout(x, p=0.5)
v_output = self.fc_v(x)
theta_output = self.fc_theta(x)
return v_output, theta_output
# 모델 인스턴스 생성
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
# 손실 함수 및 최적화기 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 훈련 함수
def train(model, train_loader, optimizer, criterion):
model.train()
total_loss = 0
for data, v_target, theta_target in train_loader:
data = data.to(device)
v_target = v_target.to(device)
theta_target = theta_target.to(device)
optimizer.zero_grad()
v_output, theta_output = model(data)
loss_v = criterion(v_output, v_target)
loss_theta = criterion(theta_output, theta_target)
loss = loss_v + loss_theta # 두 손실의 합
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
# 평가 함수
def evaluate(model, X_test, y_v_test, y_theta_test):
model.eval()
with torch.no_grad():
v_output, theta_output = model(X_test.to(device))
v_pred = torch.argmax(v_output, dim=1)
theta_pred = torch.argmax(theta_output, dim=1)
correct_v = (v_pred == y_v_test.to(device)).sum().item()
correct_theta = (theta_pred == y_theta_test.to(device)).sum().item()
total = len(X_test)
return (correct_v / total, correct_theta / total)
# 훈련 과정
epochs = 300
for epoch in range(1, epochs + 1):
loss = train(model, train_loader, optimizer, criterion)
v_accuracy, theta_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor)
if epoch % 10 == 0:
print(f'Epoch: {epoch}, Loss: {loss:.4f}, v Accuracy: {v_accuracy:.4f}, Theta Accuracy: {theta_accuracy:.4f}')
# 최종 평가
final_v_accuracy, final_theta_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor)
print(f'Final v Accuracy: {final_v_accuracy:.4f}, Final Theta Accuracy: {final_theta_accuracy:.4f}')

라벨링을 세분화했지만 성능은 더 하락했습니다. 반대로 라벨링을 더 크게하면 정확도 성능이 더 좋아질수도 있겠습니다. 하지만 라벨의 개수를 줄이는 것은 문제가 달라지므로 하지 않겠습니다.
그럼 이번에는 파생변수를 사용해봅니다. log로 감싸줍니다.
1
2
v_ranges = define_ranges(1, 20, 4)
theta_ranges = define_ranges(np.log(5), np.log(85), 3)

구간을 먼저 나누고 로그로 감싸줍니다.
1
2
3
v_ranges = define_ranges(1, 20, 4)
theta_ranges = define_ranges(5, 85, 3)
theta_ranges = [(np.log(theta_range[0]), np.log(theta_range[1])) for theta_range in theta_ranges]

둘 사이에 차이는 별로 없어보입니다.
그럼 이제 지수함수
1
2
v_ranges = define_ranges(1, 20, 4)
theta_ranges = define_ranges(np.exp(5 / 100), np.exp(85/100), 3) # 값의 폭발을 방지하기 위해 스케일 조정

루트
1
theta_ranges = define_ranges(np.sqrt(5), np.sqrt(85), 3)

이들 전부다 theta에 관한 accuracy가 0.5를 넘지 못하므로 의미가 없었습니다.
그럼 이제 sine, cosine값으로 변환.
1
2
theta_sine_ranges = define_ranges(np.sin(np.radians(5)), np.sin(np.radians(85)), 3)
theta_cosine_ranges = define_ranges(np.cos(np.radians(5)), np.cos(np.radians(85)), 3)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 생성 및 전처리
def calculate_distance(v, theta):
g = 9.81 # 중력 가속도 m/s^2
theta_rad = np.radians(theta)
return (v ** 2) * np.sin(2 * theta_rad) / g
# v와 theta 구간 정의
# v는 v1부터 vmax까지 중 n개의 구간으로 나눈다.
# 인풋: N0, Nmax, n
def define_ranges(N0, Nmax, n):
ranges = []
for i in range(n):
N_range = (N0 + (Nmax - N0) / n * i, N0 + (Nmax - N0) / n * (i + 1))
ranges.append(N_range)
return ranges
v_ranges = define_ranges(1, 20, 4)
theta_sine_ranges = define_ranges(np.sin(np.radians(5)), np.sin(np.radians(85)), 3)
theta_cosine_ranges = define_ranges(np.cos(np.radians(5)), np.cos(np.radians(85)), 3)
print(v_ranges)
print(theta_sine_ranges)
print(theta_cosine_ranges)
# 데이터 생성
data = []
labels_v = []
labels_theta = []
for v_range in v_ranges:
for theta_sine_range in theta_sine_ranges:
for theta_cosine_range in theta_cosine_ranges:
for _ in range(300):
v = np.random.uniform(v_range[0], v_range[1])
theta_sine = np.random.uniform(theta_sine_range[0], theta_sine_range[1])
theta_cosine = np.random.uniform(theta_cosine_range[0], theta_cosine_range[1])
distance = calculate_distance(v, np.degrees(np.arcsin(theta_sine)))
data.append([distance])
labels_v.append(v_ranges.index(v_range))
labels_theta.append((theta_sine_ranges.index(theta_sine_range), theta_cosine_ranges.index(theta_cosine_range)))
# 데이터를 NumPy 배열로 변환
X = np.array(data)
y_v = np.array(labels_v)
y_theta = np.array(labels_theta)
# 데이터 분할 및 스케일링
X_train, X_test, y_v_train, y_v_test, y_theta_train, y_theta_test = train_test_split(X, y_v, y_theta, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# PyTorch 텐서로 변환
X_train_tensor = torch.tensor(X_train_scaled).float()
y_v_train_tensor = torch.tensor(y_v_train).long()
y_theta_train_tensor = torch.tensor(y_theta_train).long()
X_test_tensor = torch.tensor(X_test_scaled).float()
y_v_test_tensor = torch.tensor(y_v_test).long()
y_theta_test_tensor = torch.tensor(y_theta_test).long()
# DataLoader 설정
train_dataset = TensorDataset(X_train_tensor, y_v_train_tensor, y_theta_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 신경망 모델 정의
# 변경: theta의 각 범위에 대해 개별 분류기 사용
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 100)
self.fc2 = nn.Linear(100, 100)
self.fc_v = nn.Linear(100, len(v_ranges))
self.fc_theta1 = nn.Linear(100, len(theta_sine_ranges))
self.fc_theta2 = nn.Linear(100, len(theta_cosine_ranges))
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.5)
x = F.relu(self.fc2(x))
x = F.dropout(x, p=0.5)
v_output = self.fc_v(x)
theta1_output = self.fc_theta1(x)
theta2_output = self.fc_theta2(x)
return v_output, theta1_output, theta2_output
# 모델 인스턴스 생성
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
# 손실 함수 및 최적화기 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 훈련 함수 수정
def train(model, train_loader, optimizer, criterion):
model.train()
total_loss = 0
for data, v_target, theta_target in train_loader:
data = data.to(device)
v_target = v_target.to(device)
theta1_target = theta_target[:, 0].to(device)
theta2_target = theta_target[:, 1].to(device)
optimizer.zero_grad()
v_output, theta1_output, theta2_output = model(data)
loss_v = criterion(v_output, v_target)
loss_theta1 = criterion(theta1_output, theta1_target)
loss_theta2 = criterion(theta2_output, theta2_target)
loss = loss_v + loss_theta1 + loss_theta2
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 평가 함수
def evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor):
model.eval()
with torch.no_grad():
v_output, theta1_output, theta2_output = model(X_test_tensor.to(device))
v_pred = torch.argmax(v_output, dim=1)
theta1_pred = torch.argmax(theta1_output, dim=1)
theta2_pred = torch.argmax(theta2_output, dim=1)
correct_v = (v_pred == y_v_test_tensor.to(device)).sum().item()
correct_theta1 = (theta1_pred == y_theta_test_tensor[:, 0].to(device)).sum().item()
correct_theta2 = (theta2_pred == y_theta_test_tensor[:, 1].to(device)).sum().item()
total_samples = len(X_test_tensor)
accuracy_v = correct_v / total_samples
accuracy_theta1 = correct_theta1 / total_samples
accuracy_theta2 = correct_theta2 / total_samples
# print(f"Validation results: v Accuracy: {accuracy_v:.4f}, Theta1 Accuracy: {accuracy_theta1:.4f}, Theta2 Accuracy: {accuracy_theta2:.4f}")
return accuracy_v, accuracy_theta1, accuracy_theta2
# 훈련 과정
epochs = 500
for epoch in range(1, epochs + 1):
loss = train(model, train_loader, optimizer, criterion)
v_accuracy, theta1_accuracy, theta2_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor) # Updated to unpack three values
if epoch % 10 == 0:
print(f'Epoch: {epoch}, Loss: {loss:.4f}, v Accuracy: {v_accuracy:.4f}, Theta1 Accuracy: {theta1_accuracy:.4f}, Theta2 Accuracy: {theta2_accuracy:.4f}') # Updated print statement to reflect three accuracies
# 최종 평가
final_v_accuracy, final_theta1_accuracy, final_theta2_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor) # Updated to unpack three values
print(f'Final v Accuracy: {final_v_accuracy:.4f}, Final Theta1 Accuracy: {final_theta1_accuracy:.4f}, Final Theta2 Accuracy: {final_theta2_accuracy:.4f}') # Updated print statement

개선되지 않았습니다.
그래도 혹시 몰라서, hidden-layer를 더 깊게 만들어봅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 생성 및 전처리
def calculate_distance(v, theta):
g = 9.81 # 중력 가속도 m/s^2
theta_rad = np.radians(theta)
return (v ** 2) * np.sin(2 * theta_rad) / g
# v와 theta 구간 정의
# v는 v1부터 vmax까지 중 n개의 구간으로 나눈다.
# 인풋: N0, Nmax, n
def define_ranges(N0, Nmax, n):
ranges = []
for i in range(n):
N_range = (N0 + (Nmax - N0) / n * i, N0 + (Nmax - N0) / n * (i + 1))
ranges.append(N_range)
return ranges
v_ranges = define_ranges(1, 20, 4)
theta_sine_ranges = define_ranges(np.sin(np.radians(5)), np.sin(np.radians(85)), 3)
theta_cosine_ranges = define_ranges(np.cos(np.radians(5)), np.cos(np.radians(85)), 3)
print(v_ranges)
print(theta_sine_ranges)
print(theta_cosine_ranges)
# 데이터 생성
data = []
labels_v = []
labels_theta = []
for v_range in v_ranges:
for theta_sine_range in theta_sine_ranges:
for theta_cosine_range in theta_cosine_ranges:
for _ in range(300):
v = np.random.uniform(v_range[0], v_range[1])
theta_sine = np.random.uniform(theta_sine_range[0], theta_sine_range[1])
theta_cosine = np.random.uniform(theta_cosine_range[0], theta_cosine_range[1])
distance = calculate_distance(v, np.degrees(np.arcsin(theta_sine)))
data.append([distance])
labels_v.append(v_ranges.index(v_range))
labels_theta.append((theta_sine_ranges.index(theta_sine_range), theta_cosine_ranges.index(theta_cosine_range)))
# 데이터를 NumPy 배열로 변환
X = np.array(data)
y_v = np.array(labels_v)
y_theta = np.array(labels_theta)
# 데이터 분할 및 스케일링
X_train, X_test, y_v_train, y_v_test, y_theta_train, y_theta_test = train_test_split(X, y_v, y_theta, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# PyTorch 텐서로 변환
X_train_tensor = torch.tensor(X_train_scaled).float()
y_v_train_tensor = torch.tensor(y_v_train).long()
y_theta_train_tensor = torch.tensor(y_theta_train).long()
X_test_tensor = torch.tensor(X_test_scaled).float()
y_v_test_tensor = torch.tensor(y_v_test).long()
y_theta_test_tensor = torch.tensor(y_theta_test).long()
# DataLoader 설정
train_dataset = TensorDataset(X_train_tensor, y_v_train_tensor, y_theta_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 신경망 모델 정의
# 변경: theta의 각 범위에 대해 개별 분류기 사용
# 변경2: 더 깊게. 4개의 은닉층 사용
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 100) # First hidden layer
self.fc2 = nn.Linear(100, 150) # Second hidden layer, increased size
self.fc3 = nn.Linear(150, 100) # Third hidden layer
self.fc4 = nn.Linear(100, 50) # Fourth hidden layer
self.fc_v = nn.Linear(50, len(v_ranges)) # Output layer for v
self.fc_theta1 = nn.Linear(50, len(theta_sine_ranges)) # Output layer for theta1 (sine ranges)
self.fc_theta2 = nn.Linear(50, len(theta_cosine_ranges)) # Output layer for theta2 (cosine ranges)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.dropout(x, p=0.5) # Apply dropout after the second layer
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
x = F.dropout(x, p=0.5) # Apply dropout before the final layers
v_output = self.fc_v(x)
theta1_output = self.fc_theta1(x)
theta2_output = self.fc_theta2(x)
return v_output, theta1_output, theta2_output
# 모델 인스턴스 생성
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
# 손실 함수 및 최적화기 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 훈련 함수 수정
def train(model, train_loader, optimizer, criterion):
model.train()
total_loss = 0
for data, v_target, theta_target in train_loader:
data = data.to(device)
v_target = v_target.to(device)
theta1_target = theta_target[:, 0].to(device)
theta2_target = theta_target[:, 1].to(device)
optimizer.zero_grad()
v_output, theta1_output, theta2_output = model(data)
loss_v = criterion(v_output, v_target)
loss_theta1 = criterion(theta1_output, theta1_target)
loss_theta2 = criterion(theta2_output, theta2_target)
loss = loss_v + loss_theta1 + loss_theta2
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 평가 함수
def evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor):
model.eval()
with torch.no_grad():
v_output, theta1_output, theta2_output = model(X_test_tensor.to(device))
v_pred = torch.argmax(v_output, dim=1)
theta1_pred = torch.argmax(theta1_output, dim=1)
theta2_pred = torch.argmax(theta2_output, dim=1)
correct_v = (v_pred == y_v_test_tensor.to(device)).sum().item()
correct_theta1 = (theta1_pred == y_theta_test_tensor[:, 0].to(device)).sum().item()
correct_theta2 = (theta2_pred == y_theta_test_tensor[:, 1].to(device)).sum().item()
total_samples = len(X_test_tensor)
accuracy_v = correct_v / total_samples
accuracy_theta1 = correct_theta1 / total_samples
accuracy_theta2 = correct_theta2 / total_samples
# print(f"Validation results: v Accuracy: {accuracy_v:.4f}, Theta1 Accuracy: {accuracy_theta1:.4f}, Theta2 Accuracy: {accuracy_theta2:.4f}")
return accuracy_v, accuracy_theta1, accuracy_theta2
# 훈련 과정
epochs = 300
for epoch in range(1, epochs + 1):
loss = train(model, train_loader, optimizer, criterion)
v_accuracy, theta1_accuracy, theta2_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor) # Updated to unpack three values
if epoch % 10 == 0:
print(f'Epoch: {epoch}, Loss: {loss:.4f}, v Accuracy: {v_accuracy:.4f}, Theta1 Accuracy: {theta1_accuracy:.4f}, Theta2 Accuracy: {theta2_accuracy:.4f}') # Updated print statement to reflect three accuracies
# 최종 평가
final_v_accuracy, final_theta1_accuracy, final_theta2_accuracy = evaluate(model, X_test_tensor, y_v_test_tensor, y_theta_test_tensor) # Updated to unpack three values
print(f'Final v Accuracy: {final_v_accuracy:.4f}, Final Theta1 Accuracy: {final_theta1_accuracy:.4f}, Final Theta2 Accuracy: {final_theta2_accuracy:.4f}') # Updated print statement

개선되지 않았네요.
데이터를 1차함수에서 로그로, 지수로, 루트로 각각 바꿔봤는데 별 효과가 없었습니다. 1개의 각도를 2개의 거리 차원으로 바꿔봤는데 별 효과가 없었습니다. 그리고 히든레이어를 단순히 늘려봤는데 효과가 없었습니다.
그럼 뭘 할까 곰곰히 생각해보니… 2번째 문제정의(이전 포스팅의 문제)를 풀 때도 mlp로는 성능이 잘 나오다가 신경망으로 풀려고 하니 성능이 갑자기 40%로 하락했었습니다. 그걸 간과하고 해결하지 않고 온게 문제였던것 같네요. 오히려 멀티라벨보다 싱글라벨 문제였던 2번째 문제가 상대적으로 쉬웠음에도 신경망 방식이 mlp보다 제 역할을 못하는 걸 확인했었으니까요.
그리고 chatgpt가 했던 제안 중 제가 빠뜨린 것이 있었습니다.


gpt가 mlp를 사용할 것을 제안했었고, 고급신경망 구조(resnet과 attention메커니즘;아마도transformer..?)를 추천했었습니다.
역시나 비선형 문제에는 mlp가 보편적으로 괜찮은 성능을 내주나봅니다.
그리고 resnet이나 attention구조는 신경망이 깊고 무거운 만큼 분명히 지금보다 상대적으로 잘 학습할 것 같기는 합니다.
다음 포스팅에서 이어서 진행하겠습니다.
감사합니다.
