Unity에서 ML-Agent로 커스텀 환경(축구공 굴리기) 훈련시키기

안녕하세요, 이번 포스팅은 바로 ML-Agent를 커스텀 환경에서 훈련시켜보는 주제를 다뤄보겠습니다. ML-Agent 패키지 설치, 그리고 파이썬 환경 설치가 안되신 분은 지난 포스팅들을 참조하셔서 환경 세팅을 하실 수 있습니다! 설치는 다 되셨나요? 그럼, 시작하겠습니다.
정말 간단한 게임을 한번 만들어보겠습니다. 바로 공을 굴려 목표지점으로 움직이는 게임입니다. 공은 Agent가 되어 Target 지점으로 계속 도달해서 보상을 얻게 됩니다. Target지점에 도달하면 새로운 Target지점이 랜덤 위치에 만들어집니다. 만일 움직이는 Floor 위를 벗어나 떨어진다면 그 동안 받았던 보상만 가지고 episode가 종료되며, 재시작 합니다.Agent가 받는 sensing은 Target의 위치(3 space), Agent자신의 위치(3 space), 그리고 Agent자신의 2차원 속도벡터(2 space)입니다. 그래서 총 8개의 Observation space를 가집니다. 그리고 Agent가 행동하는 Action은 x축 Continuous Action과 y축 Continuous Action의 총 2개의 Continuous Action space를 가집니다.
다음과 같이 만들어줍니다. 3d Plane, Cube, Sphere를 만들고 보기좋게 material도 입혀줍니다. (축구공 무늬 material은 mlagent 경로 내에 있습니다.)
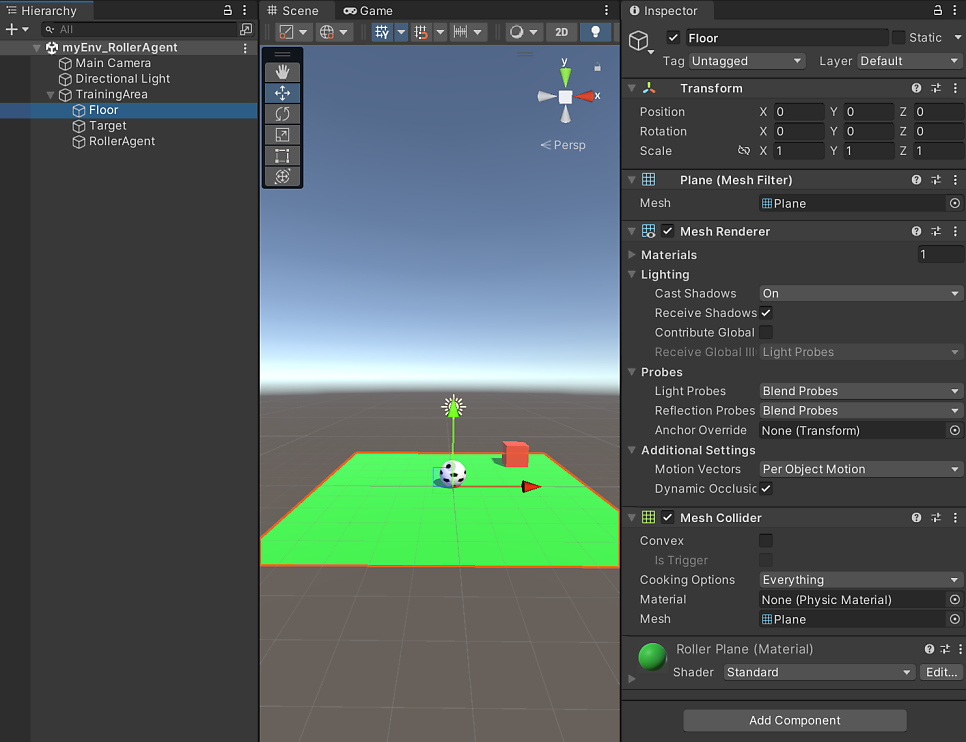
Plane은 Floor로 이름 짓고 아래와 같이 세팅합니다.
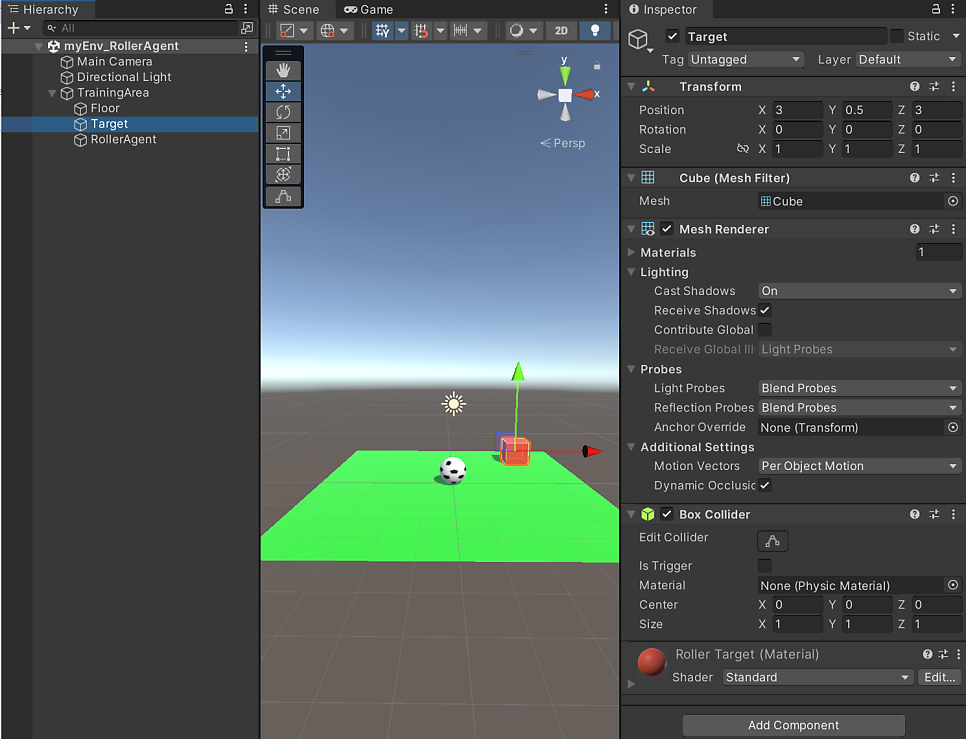
Cube는 Target이며 아래와 같이 맞춰줍니다.
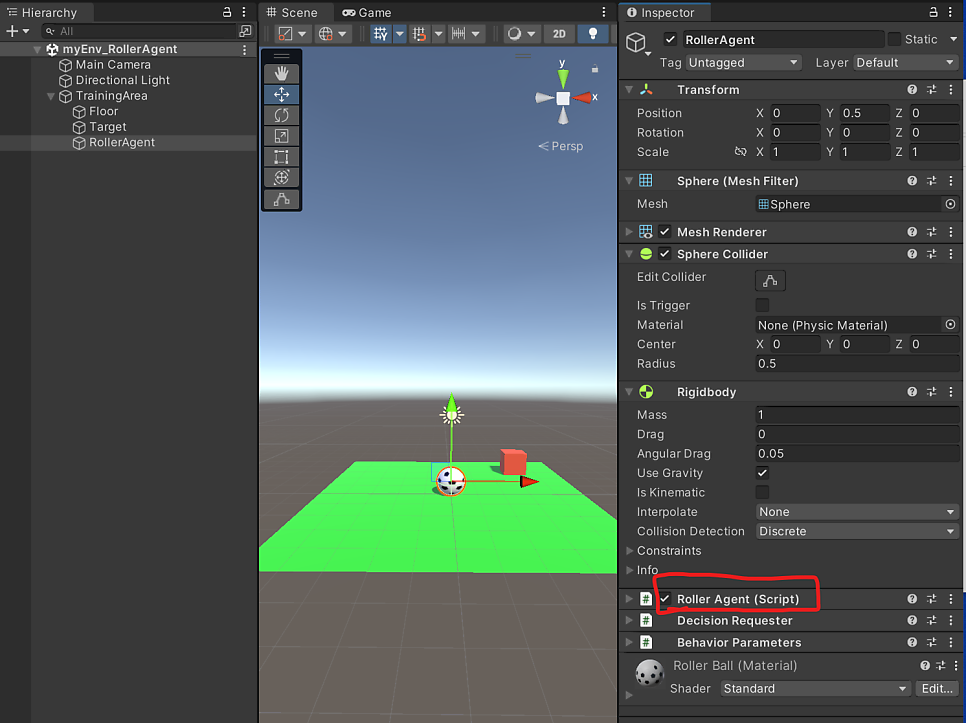
- RollerAgent 스크립트(우리가 직접 작성)
- DecisionRequester(ML-Agent 내장 컴포넌트)
- Behavior Parameters(ML-Agent 내장 컴포넌트)
RollerAgent 스크립트는 아래와 같이 작성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class RollerAgent : Agent
{
Rigidbody rBody;
void Start()
{
rBody = GetComponent();
}
public Transform Target;
public override void OnEpisodeBegin()
{
// 만약 에이전트가 떨어졌다면 운동량을 0으로 만듦
if (this.transform.localPosition.y < 0)
{
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3(0, 0.5f, 0);
}
// 타겟을 새 위치로 이동
Target.localPosition = new Vector3(Random.value * 8 - 4,
0.5f,
Random.value * 8 - 4);
}
public override void CollectObservations(VectorSensor sensor)
{
// 타겟과 에이전트 위치
sensor.AddObservation(Target.localPosition);
sensor.AddObservation(this.transform.localPosition);
// 에이전트 속도
sensor.AddObservation(rBody.velocity.x);
sensor.AddObservation(rBody.velocity.z);
}
public float forceMultiplier = 10;
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// 액션, 크기 = 2
Vector3 controlSignal = Vector3.zero;
controlSignal.x = actionBuffers.ContinuousActions[0];
controlSignal.z = actionBuffers.ContinuousActions[1];
rBody.AddForce(controlSignal * forceMultiplier);
// 보상
float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition);
// 타겟에 도달
if (distanceToTarget < 1.42f)
{
SetReward(1.0f);
EndEpisode();
}
// 플랫폼에서 떨어짐
else if (this.transform.localPosition.y < 0)
{
EndEpisode();
}
}
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActionsOut = actionsOut.ContinuousActions;
continuousActionsOut[0] = Input.GetAxis("Horizontal");
continuousActionsOut[1] = Input.GetAxis("Vertical");
}
}
이제 게임 환경이 제대로 갖추어졌는지 키보드 인풋으로 확인해보겠습니다. 이건 휴리스틱이라고 합니다. ㅎㅎ
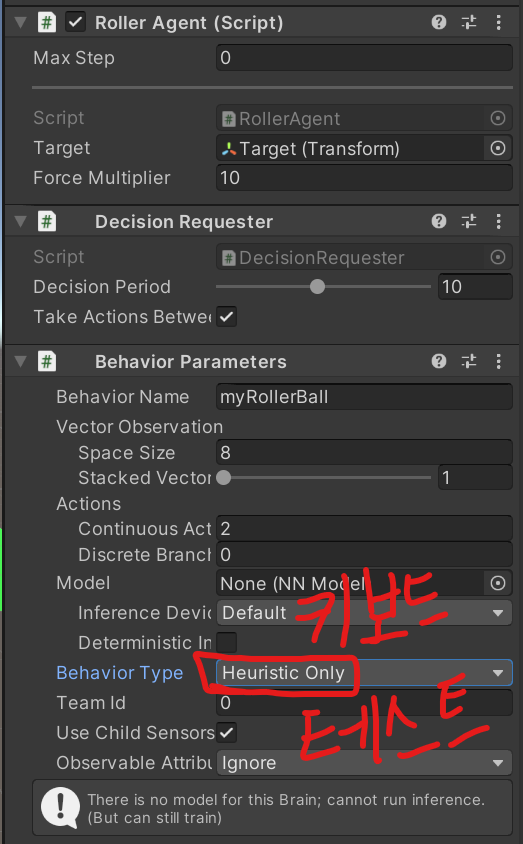

play버튼을 누르고 아래와 같이 키보드 방향키로 이리저리 x축, z축 방향 움직임을 입력해서 플레이해보았습니다. target에 도달하거나 Floor 밖으로 떨어지면 게임이 리셋되는 메커니즘이 잘 작동하는 것을 확인했습니다.
[영상]
이제 훈련을 시작해봅시다.
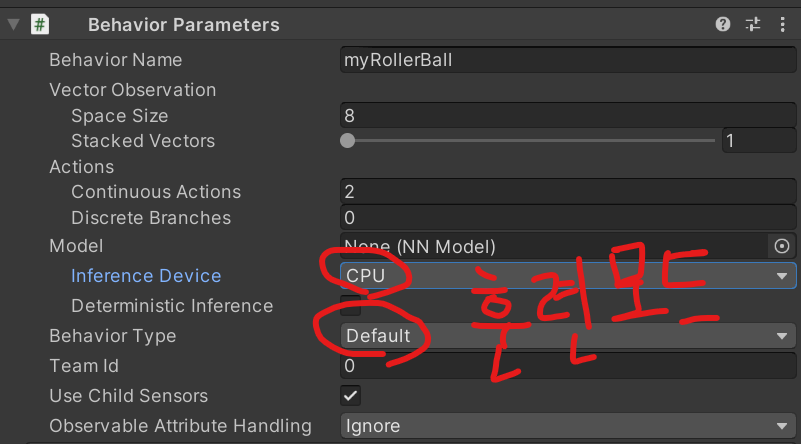
아래와 같이 추론 디바이스를 CPU로 변경하고, Behavior Type도 휴리스틱이 아닌 디폴트(훈련모드)로 바꿨습니다.

훈련 Config는 아래와 같이 만듭니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
behaviors:
myRollerBall:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000
이제 mlagent-learn으로 위 config대로 훈련을 진행해봅니다.
1
mlagents-learn config/rollerball_config.yaml --run-id=RollerBall
[영상]
왠만큼 loss가 줄었을 때 시간관계 상 중단했습니다. max_steps를 500000으로 설정했는데, 100000에서 중단해도 괜찮은 것 같습니다. (유니티에서 Play버튼을 다시 눌러서 중지하고 명령창에서 ctrl + c 로 중단해줬습니다.) 이제 훈련이 완료된 신경망 가중치를 불러오고 추론모드로 설정해서 테스트해봅니다.
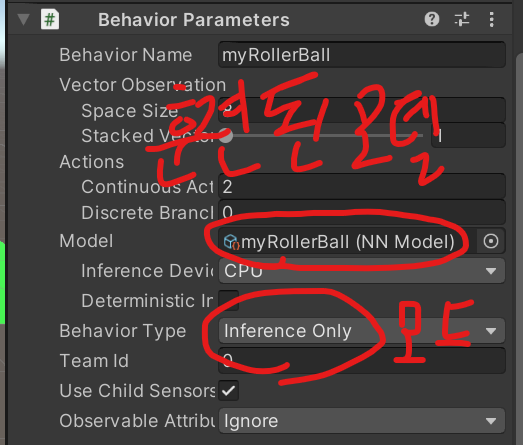
[영상]
완벽하지는 않지만 얼추 게임에서 의도한 솔루션을 학습한 것 같습니다.
다르게 쉽게 변경해보고 싶으신 분은 예를 들어 Target의 위치에 y축(위 방향) 값도 +값으로 넣어주고, agent에게 jump(y축 위 방향) 움직임도 가능하도록 변경하거나 Target을 여러개 만들거나 하는 시도도 있을 것 같습니다. 그 외에는 trainer_type과 파라미터를 변경하거나 multi-agent로 훈련을 동시에 진행하는 것도 해보면 좋을 것 같습니다.

오늘은 커스텀 환경을 간단히 구성하고 훈련을 진행해보았습니다. 감사합니다.

참고자료) https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Learning-Environment-Create-New.md https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Getting-Started.md